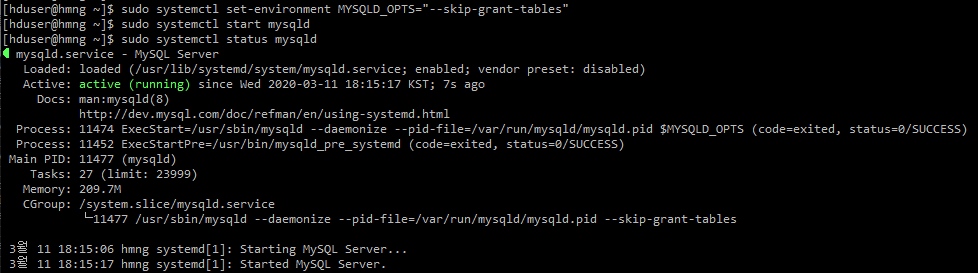
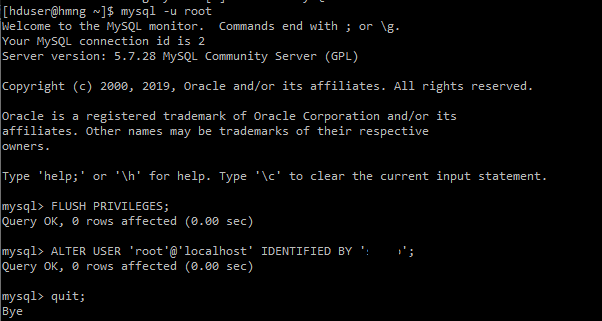
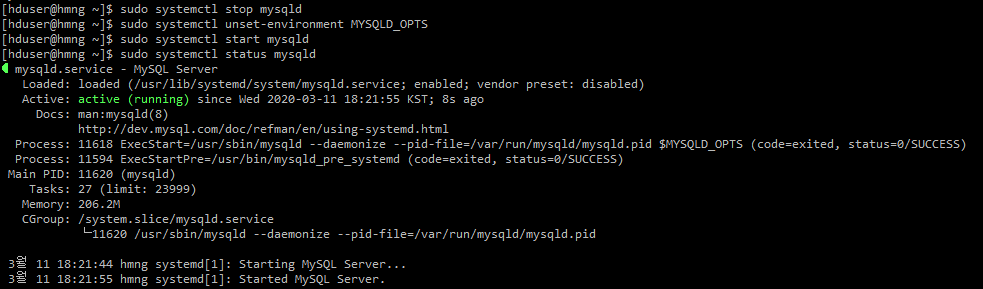
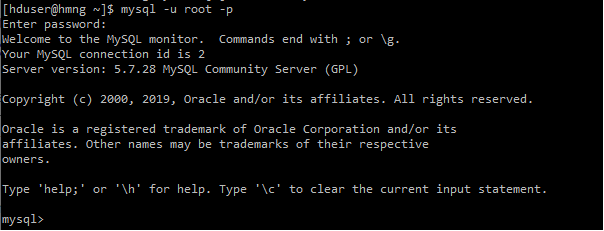
자율주행 관련 비즈니스 도메인 분석이 필요하여 정리하였던 자료입니다.
여기 저기에서 퍼온 내용을 모아둔 것이라 문체가 일관성없고 설명이 빈약한 경우도 있지만
그냥 참고용으로 포스팅해봅니다.
| 용어 구분 | 기관 및 관련 표준 |
| 용어 | 국제자동차기술자협회 |
| 영문 약어 | SAE |
| 영문 Full name | Society of Automotive Engineers |
| 설명 | 자율주행 관련 표준을 정의한 협회. 항공우주, 자동차 및 상용차 업계에서 종사하는 엔지니어와 관련 기술 전문가로 구성된 글로벌 협회. 평생 교육과 임의 표준 개발 부문에 주력 |
| 참고 | https://www.sae.org/ |
| 용어 구분 | 기관 및 관련 표준 |
| 용어 | SAE J2735 |
| 설명 | Dedicated Short Range Communications (DSRC) Message Set Dictionary |
| 참고 | https://www.sae.org/ |
| 용어 구분 | 기관 및 관련 표준 |
| 용어 | SAE J2945 |
| 설명 | Vehicle-to-Vehicle (V2V) 통신을 위해 OnBoard System 에 필요한 기술적 요구사항들에 대한 표준 |
| 참고 | https://www.sae.org/ |
| 용어 구분 | 자율주행 |
| 용어 | 첨단 운전자 보조 시스템 |
| 영문 약어 | ADAS |
| 영문 Full name | Advanced Driver Assistance System |
| 설명 | 감지센서가 위험사항을 감지하여 운전자에게 시각적, 청각적, 촉각적 요소를 통해 사고의 위험이 있음을 경고하고 이를 대처할 수 있도록 도와주는 시스템 하단, ADAS 종류 - 차량 자동 항법 장치 (In-vehicle navigation system) - 적응형 순향 제어 장치 (ACC, Adaptive Cruise Control or Smart Cruise Control) - 차선 유지 보조 시스템 (LDWS, Lane Departure Warning System or Lane Keeping Assist System) - 사각지대 경고 장치 (Lane Change Assistance or Blind Spot Detection) - 충돌 예방 시스템 (Collision Avoidance System or Precrash Safety System) - 지능형 속도 적응 시스템 (Intelligent speed adaptation or intelligent speed advice) - 야간 시야 시스템 (Night Vision) - 지능형 전조등 제어 (Adaptive Front Light Control) - 보행자 보호 시스템 (Pedestrian Protection System) - 자동 주차 시스템 (Automatic Parking) - 교통 표지판 인지 시스템 (Traffic Sign Recognition) - 운전자 졸음 방지 시스템 (Driver Drowsiness Detection) - 차량 통신 시스템 (Vehicular Communication Systems) - 경사로 주행 제어 (Hill Descent Control) - 전기차 주행 경고음 (Electric Vehicle Warning Sounds used in hybrids and plug-in electric vehicles) |
| 참고 | https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8B%A8_%EC%9A%B4%EC%A0%84%EC%9E%90_%EB%B3%B4%EC%A1%B0_%EC%8B%9C%EC%8A%A4%ED%85%9C |
| 용어 구분 | 자율주행 |
| 용어 | 잠김방지제동장치 |
| 영문 약어 | ABS |
| 영문 Full name | Anti-lock Braking Systems |
| 설명 | 일반 제동장치를 단 자동차는 급제동할 경우, 바퀴의 잠김 현상 때문에 바퀴가 미끄러지는 경우가 발생한다. 또한 이러한 자동차는 차제가 옆으로 쏠리는 현상이 나타나게 된다. 반면 ABS를 장착할 시, 1초에 7·8회 바퀴를 잠갔다가 풀렀다가를 반복한다. 이를 통해 빙판길을 운전할 시 짧은 거리에서 멈출 수 있다. 또한 차체가 한쪽으로 쏠리지 않기 때문에, 급제동의 위험도 나타나지 않는다 |
| 참고 | https://ko.wikipedia.org/wiki/ABS |
| 용어 구분 | 자율주행 |
| 용어 | 차선 유지 보조 시스템 |
| 영문 약어 | LDWS |
| 영문 Full name | Lane Departure Warning System or Lane Keeping Assist System |
| 설명 | LDWS는 방향지시등을 켜지 않고 차선을 변경하는 경우를 감지하여, 해당 사항을 운전자에게 알려서 주고, 능동형 차량 안전 시스템을 동작시킨다. |
| 참고 | https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8B%A8_%EC%9A%B4%EC%A0%84%EC%9E%90_%EB%B3%B4%EC%A1%B0_%EC%8B%9C%EC%8A%A4%ED%85%9C |
| 용어 구분 | 자율주행 |
| 용어 | 차선 변경 경고 |
| 영문 약어 | LCW |
| 영문 Full name | Lane Change Warning |
| 설명 | |
| 참고 | http://savari.net/technology/applications/ |
| 용어 구분 | 자율주행 |
| 용어 | 충돌 예방 시스템 |
| 영문 약어 | CAS or PSS |
| 영문 Full name | Collision Avoidance System or Precrash Safety System |
| 설명 | |
| 참고 | https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8B%A8_%EC%9A%B4%EC%A0%84%EC%9E%90_%EB%B3%B4%EC%A1%B0_%EC%8B%9C%EC%8A%A4%ED%85%9C |
| 용어 구분 | 자율주행 |
| 용어 | 차량 자세 제어 장치 |
| 영문 약어 | ESP |
| 영문 Full name | Electronic Stability Program |
| 설명 | Bosch에서 사용하는 용어로, 자동차회사마다 이름이 다르다. Bosch가 세계 최초 개발, 적용, 상용화하였음. 달리고 있는 자동차의 속도와 회전, 미끄러짐 등을 수십분의 1초 단위로 계산하여 실제 값과 운전자가 의도한 값을 비교, 계산하여 차이가 나는 경우, 브레이크와 엔진출력 등을 운전자가 의도한 만큼 제어할 수 있도록 스스로 개입해 사고를 미연에 방지하는 기술. 기존의 수동적 안전장치인 사고가 난 이후에 운전자를 보호하는 안전벨트, 에어백 등과는 달리 능동적인 안전장치의 범주에 들어가며 사고를 미연에 예방하는 기술로, 기존의 단순 ABS(Anti-lock Brake System)와 TCS(Traction Control System) 등 모든 전자장비의 유기적인 총 집약기술이라고 볼 수 있다. |
| 참고 | https://namu.wiki/w/%EC%B0%A8%EC%B2%B4%20%EC%9E%90%EC%84%B8%20%EC%A0%9C%EC%96%B4%EC%9E%A5%EC%B9%98 |
| 용어 구분 | 자율주행 |
| 용어 | 전방추돌방지 |
| 영문 약어 | FCW |
| 영문 Full name | Forward Collision Warning |
| 설명 | |
| 참고 |
| 용어 구분 | 자율주행 |
| 용어 | 경사로 주행 제어 |
| 영문 약어 | HDC |
| 영문 Full name | Hill Descent Control |
| 설명 | |
| 참고 | https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8B%A8_%EC%9A%B4%EC%A0%84%EC%9E%90_%EB%B3%B4%EC%A1%B0_%EC%8B%9C%EC%8A%A4%ED%85%9C |
| 용어 구분 | 자율주행 |
| 용어 | 교차로 이동 지원 |
| 영문 약어 | IMA |
| 영문 Full name | Intersection Movement Assist |
| 설명 | |
| 참고 | http://savari.net/technology/applications/ |
| 용어 구분 | 자율주행 |
| 용어 | 교통 표지판 인지 시스템 |
| 영문 약어 | TSR |
| 영문 Full name | Traffic Sign Recognition |
| 설명 | |
| 참고 | https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8B%A8_%EC%9A%B4%EC%A0%84%EC%9E%90_%EB%B3%B4%EC%A1%B0_%EC%8B%9C%EC%8A%A4%ED%85%9C |
| 용어 구분 | 자율주행 |
| 용어 | 도로작업알림 |
| 영문 약어 | RSA |
| 영문 Full name | Road Safety Alert |
| 설명 | |
| 참고 |
| 용어 구분 | 자율주행 |
| 용어 | 보행자 보호 시스템 |
| 영문 약어 | PPS |
| 영문 Full name | Pedestrian Protection System |
| 설명 | |
| 참고 | https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8B%A8_%EC%9A%B4%EC%A0%84%EC%9E%90_%EB%B3%B4%EC%A1%B0_%EC%8B%9C%EC%8A%A4%ED%85%9C |
| 용어 구분 | 자율주행 |
| 용어 | 비상제동경고 |
| 영문 약어 | EEBL |
| 영문 Full name | Electronic Emergency Brake Light |
| 설명 | |
| 참고 |
| 용어 구분 | 자율주행 |
| 용어 | 사각지대 경고 |
| 영문 약어 | BSW |
| 영문 Full name | Blind Spot Warning |
| 설명 | |
| 참고 | http://savari.net/technology/applications/ |
| 용어 구분 | 자율주행 |
| 용어 | 사각지대 경고 장치 |
| 영문 약어 | BSD |
| 영문 Full name | Blind Spot Detection |
| 설명 | 접근하는 자동차 그리고 사각지대에 위치한 자동차에 대한 정보를 운전자에게 제공하는 장치로 사각지대에 있는 자동차 등을 인지하지 못하고 차선을 변경하거나 근접하는 자동차로 인해 사고위험이 감지되는 경우 미연에 사고를 방지하기 위한 안전장치이다. |
| 참고 | https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8B%A8_%EC%9A%B4%EC%A0%84%EC%9E%90_%EB%B3%B4%EC%A1%B0_%EC%8B%9C%EC%8A%A4%ED%85%9C |
| 용어 구분 | 자율주행 |
| 용어 | 야간 시야 시스템 |
| 영문 약어 | |
| 영문 Full name | Night Vision |
| 설명 | https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8B%A8_%EC%9A%B4%EC%A0%84%EC%9E%90_%EB%B3%B4%EC%A1%B0_%EC%8B%9C%EC%8A%A4%ED%85%9C |
| 참고 |
| 용어 구분 | 자율주행 |
| 용어 | 운전자 졸음 방지 시스템 |
| 영문 약어 | |
| 영문 Full name | Driver Drowsiness Detection |
| 설명 | |
| 참고 | https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8B%A8_%EC%9A%B4%EC%A0%84%EC%9E%90_%EB%B3%B4%EC%A1%B0_%EC%8B%9C%EC%8A%A4%ED%85%9C |
| 용어 구분 | 자율주행 |
| 용어 | 자동 주차 시스템 |
| 영문 약어 | |
| 영문 Full name | Automatic Parking |
| 설명 | |
| 참고 | https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8B%A8_%EC%9A%B4%EC%A0%84%EC%9E%90_%EB%B3%B4%EC%A1%B0_%EC%8B%9C%EC%8A%A4%ED%85%9C |
| 용어 구분 | 자율주행 |
| 용어 | 저속 자동 긴급 제동 |
| 영문 약어 | AEB |
| 영문 Full name | Automatic Emergency Braking System |
| 설명 | 도심 저속 주행 때 장애물을 감지하면 자동으로 브레이크가 작동해 완전히 정지할 수 있도록 돕는 기능 |
| 참고 |
| 용어 구분 | 자율주행 |
| 용어 | 적응형 순향 제어 장치 |
| 영문 약어 | ACC |
| 영문 Full name | Adaptive Cruise Control or Smart Cruise Control |
| 설명 | ACC는 차량 전방에 장착된 레이다를 사용하여 앞차와의 간격을 적절하게 자동 유지하는 시스템이다. |
| 참고 | https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8B%A8_%EC%9A%B4%EC%A0%84%EC%9E%90_%EB%B3%B4%EC%A1%B0_%EC%8B%9C%EC%8A%A4%ED%85%9C |
| 용어 구분 | 자율주행 |
| 용어 | 전기차 주행 경고음 |
| 영문 약어 | |
| 영문 Full name | Electric Vehicle Warning Sounds |
| 설명 | |
| 참고 | https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8B%A8_%EC%9A%B4%EC%A0%84%EC%9E%90_%EB%B3%B4%EC%A1%B0_%EC%8B%9C%EC%8A%A4%ED%85%9C |
| 용어 구분 | 자율주행 |
| 용어 | 좌회전 지원 |
| 영문 약어 | LTA |
| 영문 Full name | Left Turn Assist |
| 설명 | |
| 참고 | http://savari.net/technology/applications/ |
| 용어 구분 | 자율주행 |
| 용어 | 주행 금지 경고 |
| 영문 약어 | DNPW |
| 영문 Full name | Do Not Pass Warning |
| 설명 | |
| 참고 | http://savari.net/technology/applications/ |
| 용어 구분 | 자율주행 |
| 용어 | 지능형 속도 적응 시스템 |
| 영문 약어 | ISA |
| 영문 Full name | Intelligent speed adaptation or intelligent speed advice |
| 설명 | |
| 참고 | https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8B%A8_%EC%9A%B4%EC%A0%84%EC%9E%90_%EB%B3%B4%EC%A1%B0_%EC%8B%9C%EC%8A%A4%ED%85%9C |
| 용어 구분 | 자율주행 |
| 용어 | 지능형 전조등 제어 |
| 영문 약어 | |
| 영문 Full name | Adaptive Front Light Control |
| 설명 | 변화하는 도로에 대해 최적의 시야를 제공하는 지능형 전조등. |
| 참고 | https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8B%A8_%EC%9A%B4%EC%A0%84%EC%9E%90_%EB%B3%B4%EC%A1%B0_%EC%8B%9C%EC%8A%A4%ED%85%9C |
| 용어 구분 | 자율주행 |
| 용어 | 차량 자동 항법 장치 |
| 영문 약어 | IVNS |
| 영문 Full name | In-Vehicle Navigation System |
| 설명 | |
| 참고 | https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8B%A8_%EC%9A%B4%EC%A0%84%EC%9E%90_%EB%B3%B4%EC%A1%B0_%EC%8B%9C%EC%8A%A4%ED%85%9C |
| 용어 구분 | 자율주행 |
| 용어 | 차량 통신 시스템 |
| 영문 약어 | |
| 영문 Full name | Vehicular Communication Systems |
| 설명 | |
| 참고 | https://ko.wikipedia.org/wiki/%EC%B2%A8%EB%8B%A8_%EC%9A%B4%EC%A0%84%EC%9E%90_%EB%B3%B4%EC%A1%B0_%EC%8B%9C%EC%8A%A4%ED%85%9C |
| 용어 구분 | 자율주행 |
| 용어 | 통제 불능 경고 |
| 영문 약어 | CLW |
| 영문 Full name | Control Loss Warning |
| 설명 | |
| 참고 |
| 용어 구분 | 자율주행 |
| 용어 | 급커브속도경보시스템 |
| 영문 약어 | CSW |
| 영문 Full name | Curve Speed Warning |
| 설명 | |
| 참고 | http://savari.net/technology/applications/ |
| 용어 구분 | 자율주행 |
| 용어 | |
| 영문 약어 | WZW |
| 영문 Full name | Work Zone Warning |
| 설명 | |
| 참고 | http://savari.net/technology/applications/ |
| 용어 구분 | 자율주행 장비 |
| 용어 | 전자 제어 유니트 |
| 영문 약어 | ECU |
| 영문 Full name | Electronic Control Unit |
| 설명 | 차량의 엔진, 자동 변속기 등의 상태를 컴퓨터로 제어하는 장치로서 차량 내부의 센서들을 관리하는 역할을 수행 |
| 참고 | https://committee.tta.or.kr/include/Download.jsp?filename=choan%2F%5B2014-338%5D+%C2%F7%B7%AE%B0%A3+%C5%EB%BD%C5%C8%AF%B0%E6%BF%A1%BC%AD%C0%C7+%B8%DE%BD%C3%C1%F6+%BE%CF%C8%A3%C8%AD+%B1%D4%B0%DD.docx |
| 용어 구분 | 자율주행 장비 |
| 용어 | 지역 동적 지도 |
| 영문 약어 | LDM |
| 영문 Full name | Local Dynamic Map |
| 설명 | 고정된 지도 정보에 차량 주위의 도로 교통 정보 및 상태 정보가 반영된 지도 데이터 베이스로서 차량으로 수신되는 메시지가 중복되었는지, 최신의 정보인지를 필터링 하는 역할을 수행 |
| 참고 | https://committee.tta.or.kr/include/Download.jsp?filename=choan%2F%5B2014-338%5D+%C2%F7%B7%AE%B0%A3+%C5%EB%BD%C5%C8%AF%B0%E6%BF%A1%BC%AD%C0%C7+%B8%DE%BD%C3%C1%F6+%BE%CF%C8%A3%C8%AD+%B1%D4%B0%DD.docx |
| 용어 구분 | 자율주행 장비 |
| 용어 | 차량 단말기 |
| 영문 약어 | OBU |
| 영문 Full name | On Board Unit |
| 설명 | 차량에 탑재되는 차량 간 통신용 모듈 OBU는 차량 간 통신을 지원하기 위해 차량 내부에 설치되는 시스템을 의미한다. 라우팅 테이블(RT)은 이웃 차량의 위치 정보 및 타임스탬프 정보를 저장한다. 테이블 정보는 이웃 차량들로부터 수신되는 메시지로부터 구성된다. 지역적인 동적 지도(LDM)는 고정된 지도 정보에 차량 주위의 도로 교통 정보 및 상태 정보가 반영된 지도 데이터 베이스로서 차량으로 수신되는 메시지가 중복되었는지, 최신의 정보인지를 필터링 하는 역할을 수행한다. 통신 제어 유니트 (CCU)은 차량 내부 및 차량 외부의 통신을 연결하는 모듈이다. 전자 제어 유니트 (ECU)는 차량의 엔진, 자동 변속기 등의 상태를 컴퓨터로 제어하는 장치로서 차량 내부의 센서들을 관리하는 역할을 수행한다. 센서는 차량 주행에 관련된 정보를 감지하는 장치이다. |
| 참고 | https://committee.tta.or.kr/include/Download.jsp?filename=choan%2F%5B2014-338%5D+%C2%F7%B7%AE%B0%A3+%C5%EB%BD%C5%C8%AF%B0%E6%BF%A1%BC%AD%C0%C7+%B8%DE%BD%C3%C1%F6+%BE%CF%C8%A3%C8%AD+%B1%D4%B0%DD.docx |
| 용어 구분 | 자율주행 장비 |
| 용어 | 통신 제어 유니트 |
| 영문 약어 | CCU |
| 영문 Full name | Communication and Control Unit |
| 설명 | 차량 내부 및 차량 외부의 통신을 연결하는 모듈 |
| 참고 | https://committee.tta.or.kr/include/Download.jsp?filename=choan%2F%5B2014-338%5D+%C2%F7%B7%AE%B0%A3+%C5%EB%BD%C5%C8%AF%B0%E6%BF%A1%BC%AD%C0%C7+%B8%DE%BD%C3%C1%F6+%BE%CF%C8%A3%C8%AD+%B1%D4%B0%DD.docx |
| 용어 구분 | 통신 규약 |
| 용어 | BSM |
| 영문 약어 | BSM |
| 영문 Full name | Basic Safety Message |
| 설명 | SAE J2735로 정의. 주행하는 차량의 안전성을 높이기 위하여, 임의의 차량으로부터 빈번하게 브로드캐스팅되는 메시지를 의미 차량 간 통신 환경에서는 각 차량은 100msec 주기로 주변의 차량에게 BSM을 브로드캐스팅 한다. 또한 각 차량 및 RSU는 브로드캐스팅되는 BSM을 수신하여, 각 차량에서 운영되고 있는 안전 서비스에 연관되는 지를 판별하고, 필요한 내부 처리 과정을 수행하게 된다. BSM은 Part 1 및 Part 2 라고 부르는 두 개의 섹션으로 구성된다. Part 1의 정보는 항상 전송되는 정보로서, 차량의 위치, 이동 방향, 현재 시간 및 차량의 상태 정보를 포함한다. Part 2는 부가적인 정보로서, 그 내용은 서비스의 형태에 의하여 결정된다. |
| 참고 | https://committee.tta.or.kr/include/Download.jsp?filename=choan%2F%5B2014-338%5D+%C2%F7%B7%AE%B0%A3+%C5%EB%BD%C5%C8%AF%B0%E6%BF%A1%BC%AD%C0%C7+%B8%DE%BD%C3%C1%F6+%BE%CF%C8%A3%C8%AD+%B1%D4%B0%DD.docx |
| 용어 구분 | 통신 규약 |
| 용어 | 프로브 차량 데이터 |
| 영문 약어 | PVD |
| 영문 Full name | Probe Vehicle Data |
| 설명 | Unicast from a vehicle to a TMC or other infrastructure.based system Similar to BSM, but contains additional vehicle status and traveling behavior data Core data frames are time & location based “Snapshots” - Snapshots contain sensor value/state at an moment in time - A single PVD Message can contain up to 32 Snapshots - Snapshots are generated based on - Periodic.time/distance traveled - "Events".when the state or status of certain Vehicle elements/systems change(on/off) (e.g. traction control system engaged) or when a pre.defined threshold is exceeded (e.g. hard braking) - Start/Stop - Vehicles generate and store Snapshots throughout their “trip” (ignition on .to ignition off) - Transmitted while in communication range of a RSU - Once the vehicle leaves communication range, and remaining messages/snapshots are deleted |
| 참고 | http://www.transportation.institute.ufl.edu/wp-content/uploads/2017/04/HNTB-SAE-Standards.pdf |
| 용어 구분 | 통신 규약 |
| 용어 | 여행자 정보 매시지 |
| 영문 약어 | TIM |
| 영문 Full name | Traveler Information Message |
| 설명 | |
| 참고 |
| 용어 구분 | 통신 규약 |
| 용어 | 신호변경알림 |
| 영문 약어 | SPaT |
| 영문 Full name | Signal Phase and Timing |
| 설명 | |
| 참고 |
| 용어 구분 | 센서 |
| 용어 | 관성측정센서 |
| 영문 약어 | IMU |
| 영문 Full name | Inertial Measurement Unit |
| 설명 | 움직이는 물체의 관성을 측정하여 전기적 신호로 출력을 내보내는 장치. 관성을 측정하여 물체가 어느 방향으로 움직이는지 알수 있음. |
| 용어 구분 | 센서 |
| 용어 | 라이더 |
| 영문 약어 | LIDAR |
| 영문 Full name | LIght Detection And Ranging |
| 설명 | 레이저 거리 측량기 등 빛의 파장의 특성을 이용하여 레이더로 탐지가 힘들것을 탐지함. 예: 주사식 스캐너 - 레이저 광선이 피사체에 반사된 뒤 다시 라이터 센서로 돌아오는 시간으로 거리를 계산 |
| 용어 구분 | 센서 |
| 용어 | 레이더 |
| 영문 약어 | RADAR |
| 영문 Full name | RAdio Detection And Ranging |
| 설명 | 전자기파를 주기적으로 쏘았을 때 물체에 부딪쳐 반사되는 전자기파를 읽어와 물체와의 거리, 움직이는 방향, 높이등을 확인하는 센서 |
| 용어 구분 | 센서 |
| 용어 | 범지구위성항법시스템 |
| 영문 약어 | GPS |
| 영문 Full name | Global Positioning System |
| 설명 | GPS 수신기는 세 개 이상의 GPS 위성으로부터 송신된 신호를 수신하여 위성과 수신기의 위치를 결정한다. 위성에서 송신된 신호와 수신기에서 수신된 신호의 시간차를 측정하면 위성과 수신기 사이의 거리를 구할 수 있는데, 이때 송신된 신호에는 위성의 위치에 대한 정보가 들어 있다. 최소한 세 개의 위성과의 거리와 각 위성의 위치를 알게 되면 삼변측량에서와 같은 방법을 이용해 수신기의 위치를 계산할 수 있다. |
| 참고 | https://ko.wikipedia.org/wiki/GPS |
| 용어 구분 | 센서 |
| 용어 | 스로틀위치센서 |
| 영문 약어 | TPS |
| 영문 Full name | Throttle Position Sensor |
| 설명 | 스로틀 위치 센서는 스로틀 축과 알체로 스로틀 바디에 장착되어 있다. 스로틀은 흡입공기 통로의 중간에 위치하며, 흡입공기량의 통로로서 운전자의 악셀 페달의 어/닫힘에 의하여 엔진에 흡입되는 공기량을 조절한다. 그리고, 이 공기량의 변화에 의하여 그에 따른 분사량과 점화가 달라지게 된다. 그러므로 스로틀 위치센서는 스로틀의 열림 각도(운전자의 가/감속의 의지)를 전압값으로 읽고 ECM에 전달하는 역할을 담당하고 있다. ECM은 이 정보로서 가속 영역, 감속 영역, 연료 컷(Fuel Cut)의 판단 및 점화제어를 하고 있다. |
| 참고 | http://blog.daum.net/815carplus/57 |
| 용어 구분 | 자율주행 네트워크 통신 |
| 용어 | RSU |
| 영문 약어 | RSU |
| 영문 Full name | Road Side Unit |
| 설명 | 노변에 설치되는 차량 간 통신을 위한 기지국 장비는 급증하는 차량 사고 및 사용자 중심의 차세대 교통 안전 서비스 제공을 목적으로 주행 중 또는 정차 중에 있는 차량 단말기(OBU, On Board Unit)와 상호 통신을 통해 보다 안정적인 서비스를 고객에게 맞춤 제공하기 위한 RF 기지국 장치 |
| 참고 | http://www.highgain.co.kr/itssolution/p1.asp?stat2=155&stat3=157 |
| 용어 구분 | 자율주행 네트워크 통신 |
| 용어 | V2X |
| 영문 약어 | V2X |
| 영문 Full name | Vehicle-to-Everything |
| 설명 | 운전 중 도로 인프라 및 다른 차량과 통신하면서 교통상황 등의 정보를 교환하거나 공유하는 기술 V2V, V2P, V2N, V2I, V2C 등이 존재함. |
| 용어 구분 | 자율주행 네트워크 통신 |
| 용어 | V2V |
| 영문 약어 | V2V |
| 영문 Full name | Vehicle-to-Vehicle |
| 설명 | 차량 간 통신 |
| 용어 구분 | 자율주행 네트워크 통신 |
| 용어 | V2P |
| 영문 약어 | V2P |
| 영문 Full name | Vehicle-to-Pedestrians |
| 설명 | 차량과 보행자 간의 통신 |
| 용어 구분 | 자율주행 네트워크 통신 |
| 용어 | V2N |
| 영문 약어 | V2N |
| 영문 Full name | Vehicle-to-Nomadic-devices |
| 설명 | 차량과 모바일 기기 간 통신 |
| 용어 구분 | 자율주행 네트워크 통신 |
| 용어 | V2I |
| 영문 약어 | V2I |
| 영문 Full name | Vehicle-to-Infrastructure |
| 설명 | 차량과 인프라 간 통신 |
| 용어 구분 | 자율주행 네트워크 통신 |
| 용어 | V2C |
| 영문 약어 | V2C |
| 영문 Full name | Vehicle-to-Center |
| 설명 | 차량과 관제센터 간의 통신 |
| 용어 구분 | 자율주행 네트워크 통신 |
| 용어 | BBU |
| 영문 약어 | BBU |
| 영문 Full name | Base Band Unit |
| 설명 | 5G 데이터 처리 장비 |
| 참고 | http://www.greened.kr/news/articleView.html?idxno=36033 |
| 용어 구분 | 자율주행 네트워크 통신 |
| 용어 | cellular V2X |
| 영문 약어 | |
| 영문 Full name | cellular V2X |
| 설명 | 차량 통신 네트워크의 표준의 한 종류 |
| 용어 구분 | 자율주행 네트워크 통신 |
| 용어 | LTE V2X |
| 영문 약어 | LTE V2X |
| 영문 Full name | |
| 설명 | V2X를 위한 통신 표준 기술로, cellular V2X 방식임. |
| 용어 구분 | 자율주행 네트워크 통신 |
| 용어 | RFU |
| 영문 약어 | RFU |
| 영문 Full name | Radio Frequency Unit |
| 설명 | 5G 기지국 |
| 참고 | http://www.greened.kr/news/articleView.html?idxno=36033 |
| 용어 구분 | 자율주행 네트워크 통신 |
| 용어 | 근거리 전용 통신 |
| 영문 약어 | DSRC |
| 영문 Full name | Dedicate Short Range Communications |
| 설명 | 차량 통신 네트워크의 표준의 한 종류 차량과 노변 기지국 간 100m이내에서 1Mbps 급의 근거리 통신이 가능하여 요금징수 및 교통량 수집과 정보 제공하는 네트워킹 톤신 기술 ITS 분야에 가장 많이 적용 예: 전자요금징수, 무정차기반 자동요금지불 서비스, Hi-pass 기반 교통정보서비스, BIS(Bus Information Service) |
| 참고 | http://transpro.tistory.com/entry/DSRC%EC%99%80-WAVE |
| 용어 구분 | 자율주행 네트워크 통신 |
| 용어 | 차량용 고속무선통신기술 |
| 영문 약어 | WAVE |
| 영문 Full name | Wireless Access in Vehicular Environments |
| 설명 | V2X를 위한 통신 표준 기술로, DSRC 방식임. 근거리 통신 표준에서 가장 활용도가 높은 IEEE 802.11p WiFi 기술을 자동차에 맞도록 개선하여 2012년에 완료한 표준임. (국내 표준) 고속(160km/h 이상)으로 주행하는 상황에서 차량 간 통신(V2V), 차량과 인프라 통신(V2I)을 지원하여 전방 도로 및 차량의 위험정보를 긴급 전송, 후속 추돌사고 등을 예방하는 안전서비스, 다차로 무정차톨링 서비스 등 다양한 차세대 지능형 교통시스템(ITS) 구축에 활용할 수 있는 차량 네트워킹 기술 |
| 참고 | http://transpro.tistory.com/entry/DSRC%EC%99%80-WAVE |
| 용어 구분 | 자율주행 네트워크 통신 |
| 용어 | WSA |
| 영문 약어 | WSA |
| 영문 Full name | WAVE Service Advertisement |
| 설명 |
| 용어 구분 | 자율주행 네트워크 통신 |
| 용어 | WSM |
| 영문 약어 | WSM |
| 영문 Full name | WAVE Short Message |
| 설명 |
| 용어 구분 | 기타 |
| 용어 | 버스 정보 시스템 |
| 영문 약어 | BIS |
| 영문 Full name | Bus Information Service |
| 설명 | 버스의 운행과 관련된 각종 정보를 실시간 수집 가공하여 버스 이용자들에게 제공하는 첨단 교통시스템으로 첨단 통신망을 도입하여 실시간 버스 운행정보 수집, 가공을 통해 정보를 제공하는 시스템입니다. 버스 이용자들에게는 각종 매체(정류소 안내기, 인터넷, 휴대폰 등)를 이용하여 버스도착예정시간, 버스위치정보 등을 제공하는 신개념 대중교통 시스템입니다. 버스운전자를 위한 노선정보, 운행 정보 등의 제공으로 차량운행 관리 서비스를 제공합니다. |
| 참고 | https://bus.jeju.go.kr/introduction/bisInfo |
| 용어 구분 | 기타 |
| 용어 | 지능형 교통 시스템 |
| 영문 약어 | ITS |
| 영문 Full name | Intelligent transportation system |
| 설명 | 도로·차량·화물 등 교통의 구성요소에 통신기술을 적용하여 교통정보를 수집·관리·제공함으로써, 교통시설의 이용효율을 극대화하고, 통행자에게 유용한 정보를 제공하여 교통 이용 편의와 교통안전을 제고하고, 에너지절감 등 환경친화적 교통체계를 구현하는 지능형교통체계입니다. |
| 참고 | http://www.c-its.kr/introduction/introduction.do |
| 용어 구분 | 기타 |
| 용어 | 지능형 교통 시스템차세대ITS |
| 영문 약어 | C-ITS |
| 영문 Full name | Cooperative-Intelligent Transportation System |
| 설명 | 차량이 주행 중 운전자에게 주변 교통상황과 급정거, 낙하물 등의 사고 위험 정보를 실시간으로 제공하는 시스템. 현(現) ITS는 교통수단과 시설이 분리된 상태에서 교통관리 또는 교통소통 중심의 정보수집 및 제공시스템인 반면에 차세대ITS(C-ITS)는 개별차량에 대하여 실시간 정보를 제공하여 돌발상황에 사전대응 및 예방이 가능합니다. |
| 참고 | http://www.c-its.kr/introduction/introduction.do |
'New Tech. > Autonomous Driving' 카테고리의 다른 글
| V2X (Vehicle-to-Everything) (0) | 2020.04.16 |
|---|---|
| ECU / CAN / LIN / OBD (0) | 2020.04.16 |
| 자율주행차 정의 및 관련 센서 (0) | 2020.04.16 |