
| [ 튜닝 전 ] |
아래 쿼리를 살펴보도록 하겠습니다.
SELECT CNT1, CNT2, CNT3, CNT4, CNT5, CNT6, CNT7, CNT8
FROM (
SELECT (SELECT COUNT(*) FROM CHG_LOGS WHERE REG_DT=:B1 AND ST_CD='0' AND LOG_LVL='1') CNT1
, (SELECT COUNT(*) FROM CHG_LOGS WHERE REG_DT=:B1 AND ST_CD='1' AND LOG_LVL='1') CNT2
, (SELECT COUNT(*) FROM CHG_LOGS WHERE REG_DT=:B1 AND ST_CD='2' AND LOG_LVL='1') CNT3
, (SELECT COUNT(*) FROM CHG_LOGS WHERE REG_DT=:B1 AND ST_CD='3' AND LOG_LVL='1') CNT4
, (SELECT COUNT(*) FROM CHG_LOGS WHERE REG_DT=:B1 AND ST_CD='4' AND LOG_LVL='1') CNT5
, (SELECT COUNT(*) FROM CHG_LOGS WHERE REG_DT=:B1 AND ST_CD='5' AND LOG_LVL='1') CNT6
, (SELECT COUNT(*) FROM CHG_LOGS WHERE REG_DT=:B1 AND ST_CD='6' AND LOG_LVL='1') CNT7
, (SELECT COUNT(*) FROM CHG_LOGS WHERE REG_DT=:B1 AND ST_CD='7' AND LOG_LVL='1') CNT8
FROM DUAL
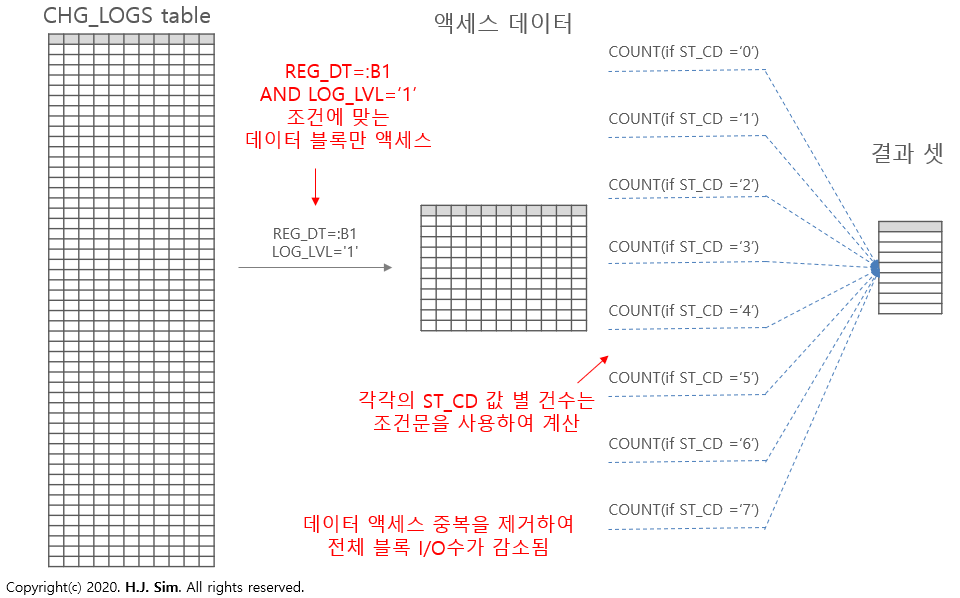
) A; CHG_LOGS 테이블의 조건별 건수를 출력하는 쿼리입니다.
ST_CD 값 별 데이터 건수를 계산하기 위해 스칼라 서브 쿼리 안에서 CHG_LOGS 테이블을 액세스하고 있습니다. 문제는 유사한 스칼라 서브 쿼리가 총 8개가 존재한다는 점입니다. 다시 말해서, CHG_LOGS 테이블을 8번 중복해서 액세스 한다는 뜻입니다.

위 쿼리의 AUTOTRACE 결과를 확인해보겠습니다.

위 쿼리의 실행계획을 살펴보면 아래와 같은 패턴(인덱스 스캔 및 테이블 랜덤 액세스)을 8번 반복해서 수행한 것을 확인할 수 있습니다.

위와 같은 반복적인 액세스 작업 때문에 과도한 블럭 읽기(109,718블럭)가 발생하고 이로 인하여 쿼리 수행 시간도 길어지게 되었습니다.
그럼, 어떤 방식으로 중복 액세스를 제거하여 쿼리 성능을 높일 수 있는지 확인해보도록 하겠습니다.
| [ 튜닝 후 ] |
아래는 튜닝 후 쿼리입니다.
SELECT NVL( SUM( CASE WHEN ST_CD='0' THEN 1 ELSE 0 END), 0) AS CNT1
, NVL( SUM( CASE WHEN ST_CD='1' THEN 1 ELSE 0 END), 0) AS CNT2
, NVL( SUM( CASE WHEN ST_CD='2' THEN 1 ELSE 0 END), 0) AS CNT3
, NVL( SUM( CASE WHEN ST_CD='3' THEN 1 ELSE 0 END), 0) AS CNT4
, NVL( SUM( CASE WHEN ST_CD='4' THEN 1 ELSE 0 END), 0) AS CNT5
, NVL( SUM( CASE WHEN ST_CD='5' THEN 1 ELSE 0 END), 0) AS CNT6
, NVL( SUM( CASE WHEN ST_CD='6' THEN 1 ELSE 0 END), 0) AS CNT7
, NVL( SUM( CASE WHEN ST_CD='7' THEN 1 ELSE 0 END), 0) AS CNT8
FROM CHG_LOGS A
WHERE REG_DT=:B1
AND LOG_LVL='1'; 중복 액세스를 피하기 위해 스칼라 서브 쿼리를 제거하였습니다. CHG_LOGS 테이블은 한 번만 액세스 하도록 변경하였으며, WHERE 절에는 각 스칼라 서브 쿼리에서 동일하게 적용되었던 조건(REG_DT=:B1 AND LOG_LVL='1')을 입력하였습니다.
그리고 CASE문을 이용하여 ST_CD 별 데이터 건수를 계산하였습니다.
위와 같이 변경된 쿼리의 AUTOTRACE 결과는 아래와 같습니다.

실행계획을 살펴보면 IX_CHG_LOG 인덱스와 CHG_LOGS 테이블을 한번씩 액세스하고 있는 것을 확인하실 수 있습니다. 액세스 중복이 제거되어 실행시간(0.02초)과 블럭 읽기(13,714블럭)가 감소된 것을 확인하실 수 있을 것입니다. 물론, 중복 제거의 방법으로 함수를 사용하여 CPU의 사용량이 증가하게 됩니다. 하지만, 쿼리에서 가장 큰 부하는 블럭 읽기이기 때문에 부하 측면에서 CPU 사용량은 상대적으로 낮은 비용이라고 판단할 수 있습니다.
지금까지 살펴봤던 SQL 튜닝 방법이 집합적 사고의 한 예라고 볼 수 있습니다. 데이터 블럭 하나하나가 퍼즐 조각이며, 각 퍼즐 조각을 최대한 적게 활용하여 멋진 작품인 결과물을 만들어내는 게 집합적 사고에 의한 쿼리문 작성인 거죠. 많은 분들이 시간적 여유를 갖고 적은 퍼즐 조각으로 멋진 작품을 탄생시키는 기쁨을 느껴보셨으면 좋겠습니다.
'Database > Oracle' 카테고리의 다른 글
| Oracle SQL 튜닝 예제 #2 - PL/SQL 제거 (1) | 2020.04.19 |
|---|---|
| 테이블 조인 방식(Table join method) (0) | 2020.04.08 |
| 오라클(Oracle) 19c 설치 (Windows 10환경) (3) | 2020.03.27 |