Hive에서도 아래와 같이 'EXPLAIN' 명령문으로 쿼리 실행계획을 확인할 수 있습니다.
hive> EXPLAIN 쿼리문;
Hive의 실행계획은 다른 DBMS에 비해 실행계획의 가독성이 떨어진다는 점이 참으로 안타까운데요.
쿼리 수행 작업을 여러 Stage로 나눠 실행하고, 각 작업 단계에서도 Map과 Reduce 태스크로 일감을 분할해 처리하는 hive의 특성상 장문의 실행계획은 다른 대안이 없는 결과라고 생각합니다.
또 하나 아쉬운 점은, 파티션 테이블의 스캔 정보가 명확하지 않다는 점입니다.
오라클의 실행계획을 예를 들어 살펴보면, 'PARTITION RANGE SINGLE'이라는 Operation으로 하나의 파티션만 액세스 된다는 것을 쉽게 알 수 있습니다.
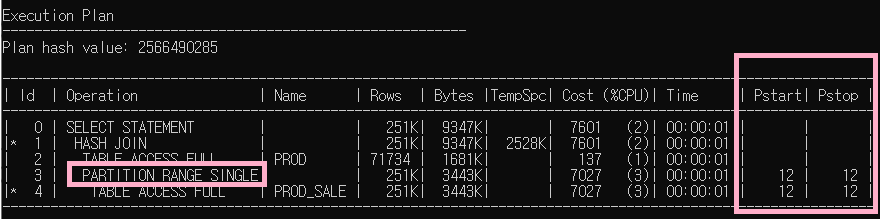
하지만, Hive에서의 실행계획에서는 PARTITION이라는 단어조차 찾아볼 수 없습니다.
그럼, 내가 작성한 쿼리문이 '테이블의 전체 데이터를 액세스 하는지?' 아니면 '조건에 맞는 파티션만 액세스(이하 Partition puruning)를 하는지?' 확인할 수 있는 방법은 없는 건가요?
방법은 두 쿼리 문의 실행계획 비교입니다.
첫 번째, WHERE 조건절 없이 전체 테이블 데이터를 SELECT 하는 쿼리의 실행계획을 확인해봅니다.
hive> EXPLAIN SELECT UID FROM ACT_TXT_DD;
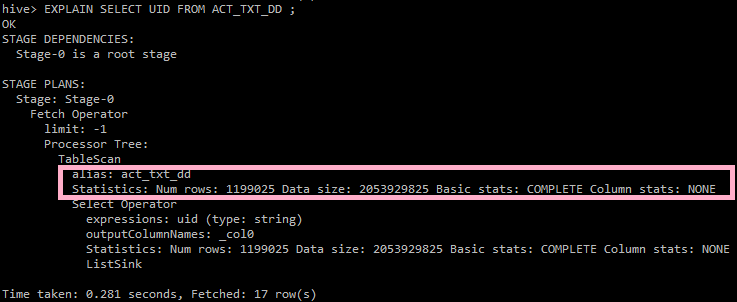
위 실행계획에서 ACT_TXT_DD 테이블의 통계정보(Statistics)를 살펴봅니다.
로우 수(Num rows)가 1,199,025건이고 데이터 크기(Data size)가 2,053,929,825 Byte이네요.
두 번째, WHERE 조건절에 파티션 컬럼의 필터링 조건이 명시된 SELECT문의 실행계획을 확인해봅니다.
hive> EXPLAIN SELECT UID FROM ACT_TXT_DD WHERE BASE_DT='20200101';
파티션 컬럼 BASE_DT의 값이 '20200101'인 데이터만 추출하는 SELECT문의 실행계획은 아래와 같습니다.

통계정보(Statistics) 상의 로우 수(Num rows)는 101,835건이고 데이터 크기(Data size)는 174,443,355 Byte입니다.
위 WHERE 조건절이 없는 SELECT문의 실행계획과 비교해서 로우 수와 데이터 크기가 적어진 것을 확인할 수 있습니다.
Partition puruning으로 테이블 스캔 범위가 적어져 위와 같은 통계정보를 출력하게 된 것입니다.
WHERE 조건절에 파티션 키 칼럼 필터링 조건을 입력했더라도, 형 변환 문제나 UDF 사용으로 인해 Partition puruning이 적용되지 않을 수도 있습니다.
HQL 수행 속도가 매우 느리다면 위와 같은 방법으로 Partition puruning 여부를 확인해 보는 것이 HQL 최적화의 한 방법이 되겠습니다.
'BigData > Hive' 카테고리의 다른 글
| Hive 2.3.6 설치 (CentOS 8) (2) | 2020.08.07 |
|---|---|
| HiveQL Tuning Case #1 - 많은 데이터는 적게 만들기 (0) | 2020.06.24 |
| ORC(Optimized Row Columnar) in 하이브(Hive) (0) | 2020.06.13 |
| 하이브(Hive) 파일 형식 (0) | 2020.06.01 |
| [Hive] java.lang.OutOfMemoryError: PermGen space 에러 (0) | 2020.03.15 |