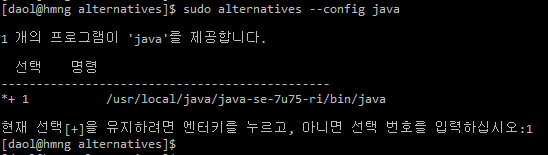
하둡의 데이터 노드를 생성하고 하둡을 실행하기 위해서는 사전 작업 및 환경 설정이 필요합니다. 관련 내용은 아래 포스팅을 참고하시면 됩니다.
> 하둡(Hadoop) 설치하기[#1] - 설치 준비
> 하둡(Hadoop) 설치하기[#2] - 하둡 환경 설정하기
당연한 얘기이지만, 하둡 테스트를 위해 가상머신에 하둡을 설치하는 이유는 클러스터를 구성 할 수 있는 서버를 확보 할 수 없기 때문입니다. Single 환경이 아닌 클러스터 환경을 구축하기 위해서는 최소한으로 1개의 관리노드와 3개의 데이터 노드가 필요한데, 일반 가정집에서 이런 환경을 구축한다는 것은 사실상 불가능합니다. 구축이 가능하더라도 시끄러운 서버의 소음과 하루종일 함께 할 인내심은 절대로 가지고 싶지 않겠죠.
아무튼, 서버 구축은 현실적으로 불가능하므로 우리는 데스크탑에서 가상환경을 구축하여 하둡을 설치하고 테스트 할 수 있습니다. 필자 또한 VirtualBox를 이용해 하둡 설치 작업을 진행하고 있습니다. VirtualBox를 이용하여 하둡을 설치를 하게되면 데이터 노드로 사용할 서버 구성을 쉽게 할 수 있다는 장점도 있습니다.
이런 장점을 살려, 지금까지 설치한 하둡 마스터 서버를 기반으로 데이터 노드 서버를 구성해보겠습니다.
참고로, 설치 테스트에 사용된 VirtualBox는 6.0.14 버전입니다.
1. 데이터 노드 서버 생성
VirtualBox의 왼쪽에는 설치된 가상머신의 목록을 보여줍니다. 지금까지 하둡 설치 및 구성이 완료된 가상머신을 종료한 후에, 가상머신 목록에서 오른쪽 버튼을 눌러 팝업 메뉴를 띄워보겠습니다.

메뉴 중에서 '복제'를 선택하면 아래와 같이 새로 생성 할 가상머신의 이름과 경로를 선택하는 창이 나타납니다. 적절한 '이름'과 '경로'를 입력해주면 됩니다. 'MAC 주소 정책'은 새로운 MAC 주소를 할당받기 위해서 '모든 네트워크 어댑터의 새 MAC 주소 생성'을 선택합니다. 설정이 완료되었으면 '다음' 버튼을 클릭합니다.

복제 방식에서는 '완전한 복제'를 선택한 후 '복제' 버튼을 클릭합니다.
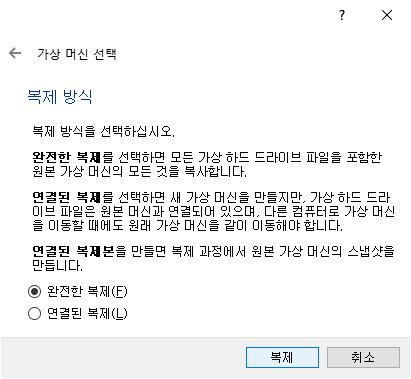
복제 작업이 진행되는 동안 progress bar를 통해 복제 작업이 진행되는 상태를 확인할 수 있습니다.

복제가 완료되면 VirtualBox 왼쪽 목록에 복제한 가상머신 Hadoop_Data1을 볼 수 있을 것입니다.

2. 데이터 노드 IP주소 및 hostname 설정
먼저, Hadoop_Data1 가상머신을 구동해보겠습니다. (IP 주소를 변경하기 전이므로 Hadoop_MST와 동시에 구동하면 IP 주소 충돌이 발생할 수 있습니다.)
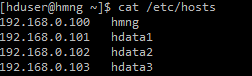
앞서 정의했던 서버 정보에 따라 IP주소를 변경해주면 됩니다.
| 서버 | 호스트명 | IP | 비고 |
| 관리 노드 | hmng | 192.168.0.100 | NameNode 및 ResourceManager 등 |
| 데이터 노드 1 | hdata1 | 192.168.0.101 | DataNode 및 NodeManager등 |
| 데이터 노드 2 | hdata2 | 192.168.0.102 | |
| 데이터 노드 3 | hdata3 | 192.168.0.103 |
필자는 IP 주소를 쉽게 변경하고자 윈도우X 환경에서 IP주소를 변경하였습니다.

이어서, hostname도 변경해보겠습니다. hostname은 /etc/hostname 파일 내용을 변경해주면 됩니다. 물론 CentOS 8 환경인 경우에 해당되는 내용입니다. 각 서버 환경에 따라 변경 작업을 진행해주면 됩니다.
sudo vi /etc/hostname
위 파일 내용을 변경하였으면, 적용하기 위해 가상머신을 재부팅해줘야 합니다.
3. SSH 설정
하둡에서는 원격 서버의 데몬을 관리하기 위해 SSH를 사용합니다. 따라서, 클러스터 내 서버간에 비밀번호 입력이 없어도 SSH 접속이 가능하도록 설정이 필요합니다.
RSA 암호화 방식으로 비밀번호 입력 없이도 원격 서버에 로그인 가능하도록 설정해보겠습니다. 우선 마스터 서버에서 RSA 공개키/개인키를 생성합니다.
> ssh-keygen


ssh-keygen 명령을 실행하고나면 위와 같이 지정된 경로에 개인키/공개키가 생성된 것을 확인할 수 있습니다.
이렇게 생성된 공개키를 모든 서버에 복사를 합니다.
> ssh-copy-id hmng
> ssh-copy-id hdata1
> ssh-copy-id hdata2
> ssh-copy-id hdata3

ssh-copy-id 명령어를 실행한 후 데이터노드 서버를 확인해보면 공개키가 생성된 것을 확인해 볼 수 있을 것입니다.

마스터서버에서 데이터노드 서버로 ssh 접속을 해보겠습니다. 비밀번호 입력없이 바로 접속이 가능하다면 정상적으로 설정된 것입니다.

여기서 주의할 점은 위 작업을 모든 서버에서 설정해줘야 한다는 점입니다.
하둡 클러스터 내 모든 서버간 SSH 통신이 필요하므로, 단방향이 아닌 양방향간에도 비밀번호 없이 접속 가능하도록 모든 서버에서 공개키/개인키를 생성한 후, 공개키를 모든 서버에 복사해줘야 합니다.
SSH 설정이 마무리 되었다면 .ssh/authorized_keys 내 파일 내용은 아래와 같은 형태일 것입니다.

4. 데이터 노드 추가
이제 데이터 노드에 대한 설정이 완료되었습니다.
Hadoop_Data1 가상머신을 종료한 후, 1. 데이터 노드 서버 생성을 참고하여 Hadoop_Data2와 Hadoop_Data3를 생성해줍니다.

복제가 완료되면 VirtualBox의 왼쪽 가상머신 목록은 아래와 같은 형상이 될 것입니다.
이어서, 2. 데이터 노드 IP주소 및 hostname 설정을 참고하여 Hadoop_Data2와 Hadoop_Data3 서버의 IP주소 및 hostname을 변경해줍니다.
5. HDFS 포맷
데스크탑이나 노트북에서 새 디스크를 사용하기 위해서는 먼저 포맷 작업을 수행해야 합니다. 하둡의 파일시스템인 HDFS도 역시 포맷 작업을 한 후에 사용이 가능합니다.
HADOOP_HOME 디렉토리로 이동한 뒤 아래 명령을 입력하여 HDFS를 포맷합니다.
> bin/hdfs namenode -format

에러 메세지 없이 마지막에 아래와 같은 로그가 표시되면 정상적으로 포맷이 완료된 것입니다.

6. 하둡 시작
이제 하둡 클러스터를 구동하기 위해서는 먼저 HDFS 프로세스를 구동한 후 YARN 프로세스를 구동해줘야 합니다.
우선 아래 명령을 입력하여 HDFS 프로세스를 실행해봅니다.
> sbin/start-dfs.sh
HDFS가 정상적으로 시작되었다면 마스터 서버에서는 NameNode와 SecondaryNameNode 자바 프로세스를 데이터 노드에서는 DataNode 자바 프로세스를 확인 할 수 있을 것입니다.


웹브라우저에서 아래 URL로 접속해보자. IP주소는 사용자가 설정한 마스터서버의 IP주소를 입력해주면 됩니다.
http://마스터서버IP:50070
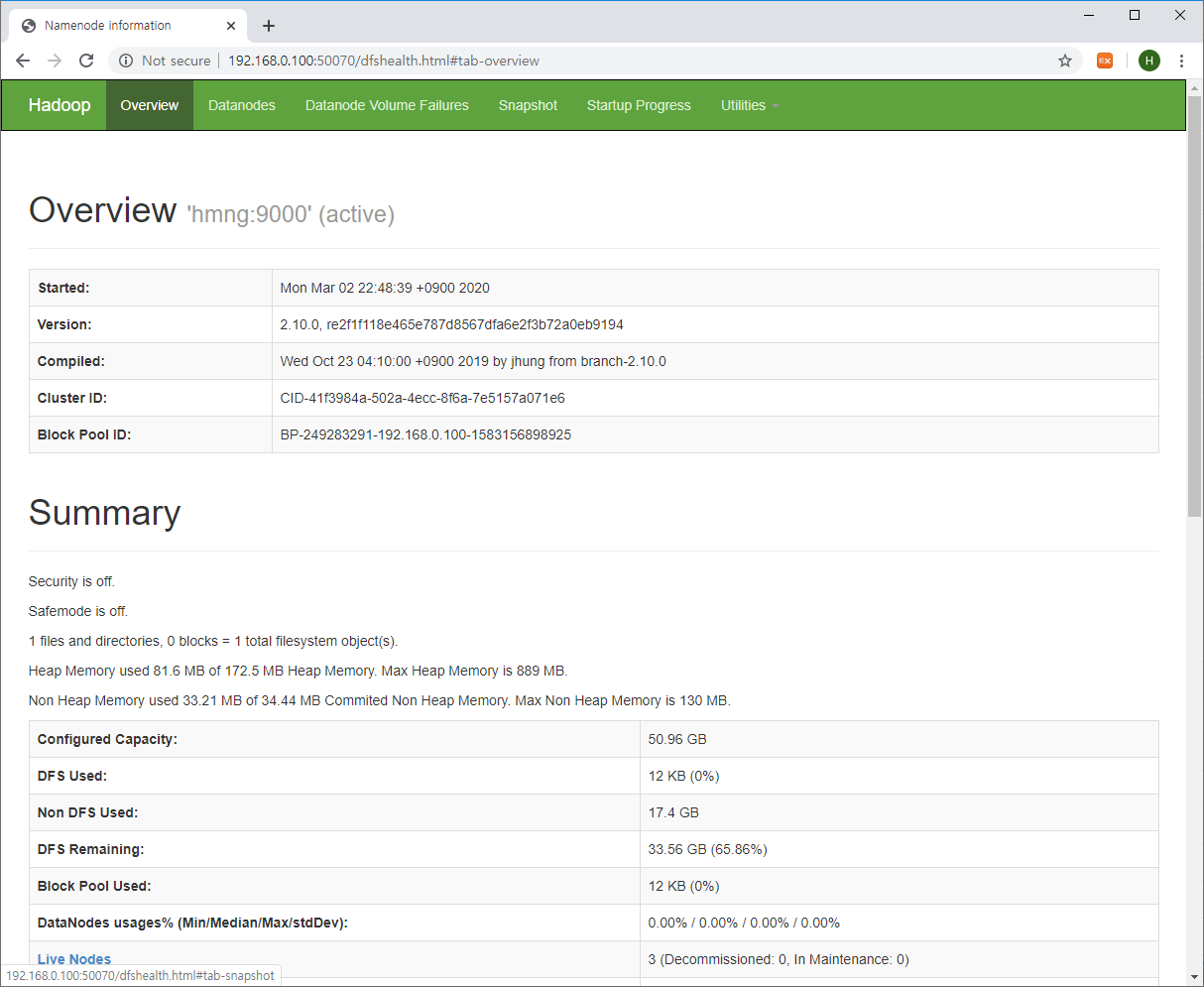
위와 같이 NameNode 정보 웹페이지가 표시되고 HDFS 정보가 정확하다면 정상적으로 HDFS가 구동된 것입니다.
이어서 아래 명령어를 입력하여 YARN 프로세스를 구동해보자.
> sbin/start-yarn.sh
YARN이 정상적으로 실행되었다면 마스터서버에서는 ResourceManager 자바 프로세스가 데이터노드 서버에서는 NodeManager 자바 프로세스를 확인할 수 있을 것이다.


다시 웹브라우저에서 아래 URL로 접속해보자. 여기서도 IP주소는 사용자가 설정한 마스터서버의 IP주소를 입력해주면 된다.
http://마스터서버IP:8088

위와 같이 ResourceManager 페이지가 표시된다면 정상적으로 YARN이 구동된 것이다.
참고로, 아래 명령어를 사용하면 한번에 HDFS와 YARN가 순차적으로 구동됩니다.
> sbin/start-all.sh
하둡 클러스터를 종료 시에는 구동 순서와 반대로 YARN 프로세스를 종료 한 후 HDFS 프로세스를 종료해줘야 합니다.
> sbin/stop-yarn.sh
> sbin/stop-dfs.sh

물론, stop-all.sh 스크립트를 실행하여 한번에 하둡 클러스터를 종료할 수 있습니다.
> sbin/stop-all.sh
이상으로 하둡 설치에 관한 포스팅을 마무리하고자 합니다.
여기에서 언급하지는 않았지만 hdfs-site.xml 파일 내 오타와 방화벽 문제(어차피 가상환경에서의 테스트라 그냥 방화벽 해제하여 해결)로 프로세스가 제대로 구동되지 않아 삽질을 좀 했었습니다. 이 포스트를 참고하여 하둡 설치를 진행하시는 분들도 필자와 같은 문제들을 직면할 수도 있습니다. 하지만, IT 업무를 수행하면서 항상 느끼는 바는 시도하지 않는 것보다는 삽질을 통해서라도 조금 더 배워 나가는 것이 본인의 캐리어를 쌓을 수 있는 더 나은 방법이라고 생각합니다. 설치 작업 중간에 여러 문제가 발생하더라도 거기서 포기하지 마십시오. 우리에게는 인터넷 검색을 할 수 있는 능력이 있으며, 도움을 요청하면 누군가는 해결의 실마리를 제공해줄 누군가가 반드시 있을 것입니다.
'BigData > Hadoop' 카테고리의 다른 글
| 맵리듀스(Map-Reduce) 데이터 흐름 (0) | 2020.05.23 |
|---|---|
| Hadoop YARN (0) | 2020.05.11 |
| HDFS 아키텍처 (0) | 2020.05.11 |
| 하둡(Hadoop) 설치하기[#2] - 하둡 환경 설정 (0) | 2020.03.01 |
| 하둡(Hadoop) 설치하기[#1] - 설치 준비 (0) | 2020.03.01 |