데이터의 가치가 높아지고 데이터 저장/관리 기술이 발전하면서 다양한 데이터베이스 소프트웨어가 출시되고 있습니다.
Hadoop 클러스터링 환경에 기반한 Hive, HBase, Spark SQL는 빅데이터 수집/분석에 대한 요구사항의 증대와 같이 사용량도 늘어가고 있습니다.
인프라 운영에 대한 리스크를 줄여주고 빠른 서비스 구축이 가능하다는 장점을 내세워 급속도로 성장을하고 있는 클라우드 서비스 플랫폼이 증가하면서 클라우드 환경의 데이터베이스도 사용이 증가하고 있습니다. 기존의 데이터베이스가 클라우드 환경에서도 서비스를 시작하는 경우도 있지만, Amazon DynamoDB, Google BigQuery, Microsoft Azure SQL Database 처럼 클라우드 플랫폼 전용 데이터베이스 서비스도 생겨나고 있습니다.
그 외에도 다양한 형태의 데이터를 관리하기 위해 NoSQL, Graph DB, Time Series DB 등의 데이터베이스도 사용량이 증가하고 있습니다.
하지만, 아직도 DBMS 시장에서 우위를 차지하고 있는 것은 역시 RDBMS입니다.

제가 예상하건데 표 형태로 데이터를 보고 싶어하는 사용자의 욕망이 바닥으로 추락하지 않는 한 RDBMS는 끝까지 건재할 것입니다.
아무튼, 이번 포스팅에서는 이 RDBMS의 성능 최적화 전략에 대해서 정리해보고자 합니다.
우선, 'RDBMS'의 성능이 좋다는 기준은 무엇일까요?
RDBMS의 목적이 동시성 제어로 다수의 사용자가 빠르게 원하는 데이터를 저장하고 추출하는 것이니, 얼마나 많은 사용자가 얼마나 빨리 데이터를 처리할 수 있느냐가 성능의 기준이 되겠습니다.
실제로 SI 프로젝트에서도 위와 같은 기준으로 성능 부하 테스트를 진행하고 있습니다.
그럼 쿼리 실행 속도가 매우 빠르면 성능상으로 문제가 없는 걸까요?
실행 속도가 빠르다는 건 표면상의 성능 기준이라고 할 수 있습니다. 정확하게 얘기하면 쿼리 실행 시 내부적으로 얼마나 많은 블럭을 I/O했는지가 성능을 판가름하는 중요한 지표가 됩니다. 모든 시스템에서 디스크 I/O는 상대적으로 느린 속도로 인하여 많은 비용을 유발하는 원인으로 인식하고 있습니다. 그래서 디스크 I/O를 줄이기 위해 버퍼에 데이터를 로딩하여 사용합니다. 하지만 버퍼는 크기의 한계가 있기 때문에 디스크 I/O를 완전히 제거할 수는 없습니다.
최소한의 블럭 I/O로 버퍼의 활용도를 높이고 디스크 I/O를 줄이는 것이 실행 속도를 빠르게 하고 성능을 높일 수 있는 궁극적인 방법이 되겠습니다.
이 포스팅에서 언급하는 내용들은 거의 다 블럭 I/O를 줄이기 위한 방법들이라고 이해하시면 됩니다.
그럼 본격적으로 RDBMS의 성능에 대해 얘기해보겠습니다.
필자가 생각하는 RDBMS에서의 성능 최적화 전략은 다음과 같습니다.
- RDBMS 성능 최적화 전략 -
1. 파라미터 튜닝 (Parameter tuning)
2. 조인 전략 (Join strategy)
3. 인덱스 전략 (Index strategy)
4. 데이터 아키텍처 전략 (Data architecture strategy)
5. SQL 튜닝 (SQL tuning)

1. 파라미터 튜닝 (Parameter tuning)
파라미터(또는 Config, 환경설정) 튜닝을 제일 먼저 언급하는 이유는 시스템 구축 초기에 완료해야 할 작업이기 때문입니다.
모든 솔루션은 설정 파일을 이용해 각 사이트 환경에 적합한 파라미터 값을 설정할 수 있는 기능을 제공합니다. (예를 들어 오라클은 init.ora, MySQL는 my.cnf 파일이 이에 해당됩니다.) 일반적인 파라미터 항목은 버퍼/캐쉬 크기, 로그 기록 위치, 블럭(페이지) 크기, 부가 기능 사용여부 또는 설정 값 등이 있을 수 있습니다.
여러 파라미터 중에서 초기 데이터베이스 생성 시에만 설정이 가능한 항목들이 있고, 데이터베이스 생성 후에도 변경이 가능한 항목들도 존재합니다. 그렇다고 추후에 변경 가능한 항목들을 마음껏 변경할 수 있다는 뜻은 아닙니다. 특히, 운영 중인 시스템의 설정 값은 더욱 더 심사숙고 해야 합니다.
검증되지 않은 설정 값 변경으로 기존에 잘 수행되던 쿼리의 실행계획이 변경되어 악성 쿼리가 난무하는 시스템을 만나게 될 수 도 있기 때문입니다.
그러면 최적화를 위해 파라미터를 어떻게 변경해야 할까요?
최선의 방법은 reference를 참조를 해서 연구하고 테스트 후 적용하는겁니다. 각 DBMS 솔루션은 사용자들을 위한 커뮤니티나 서포트 페이지를 통해서 고객 문의를 지원해주고 있습니다. 그곳에서 빈번하게 수정해야 된다고 언급되는 파라미터가 있다면 테스트 후 적용해 볼 가치가 높은 편이라고 볼 수 있습니다.
물론 설정 값을 변경하는 것은 그저 타이핑을 하면 되는 쉬운 것이지만, 그 값을 어떤 항목으로 채워야 하는지 알아내는 것은 쉬운 일이 아닙니다. 이럴 때는 솔루션 고객센터나 데이터베이스 컨설팅 업체의 도움을 받아야 할 것입니다. 이것도 비용상의 문제로 어렵다면 DBMS 선택 시 안정화된 버전을 설치하는 것이 쉬운 방법이 될 것입니다.
파라미터를 변경하는 주된 이유는 아직 안정화가 안된 버전에서 신규 기능에 의해 잘 알려지지 않은 버그를 해결하기 위한 경우가 많기 때문입니다.
2. 조인 전략 (Join strategy)
일반적으로 우리가 알고 있는 조인 종류(Type)는 다음과 같습니다.

위 조인 종류는 두 테이블을 조인 시 한 쪽에만 존재하는 데이터를 결과 데이터 셋에 포함시킬지 여부에 따라 조인을 구분한다고 생각하시면 됩니다. 자세한 내용은 아래 포스팅을 참고 바랍니다.
테이블 조인 종류(Table Join Type)
데이터베이스에서 데이터는 다수의 테이블에 나뉘어 저장되어 있습니다. 데이터의 중복을 제거하고 무결성을 보장하기 위해서 데이터 성격에 따라 분류하여 테이블에 저장을 하는 겁니다. 이렇게 테이블별로 분리..
sparkdia.tistory.com
그리고 조인 방식(Method)에 의해서도 조인을 구분할 수 있습니다.

데이터베이스 내부에서 각각의 Row를 매핑 시 사용되는 방식에 의해 조인을 구분할 수 있는겁니다.
쿼리 실행 시 옵티마이저가 다양한 조인 방식 중에서 어떤 방식을 채택하느냐에 따라 쿼리 성능이 크게 달라질 수 있게 됩니다. 일반적으로 데이터 건수가 적은 경우에는 Nested loops join을 사용하고, 데이터 건수가 많은 경우에는 Hash join을 사용합니다. 그리고 조인 대상 테이블 중에 데이터 건수가 적은 테이블부터 액세스를 해야 더 좋은 성능을 보장할 수 있습니다.
자세한 조인 방식에 대한 설명은 아래 포스팅을 참고 바랍니다.
테이블 조인 방식(Table join method)
테이블 조인 방식은 테이블의 각 로우를 매핑 시 어떤 메커니즘을 사용하느냐에 따라 조인을 구분하는 겁니다. 데이터 셋의 건수 등을 기반으로 옵티마이져가 적합한 조인 메커니즘을 선택하여 실행 계획을 생성하..
sparkdia.tistory.com
3. 인덱스 전략 (Index strategy)
인덱스는 테이블의 데이터를 빠르게 액세스하기 위한 목적으로 만들어진 객체입니다.
흔히 비유하기를 책 분류기호를 이용해 서가에 순서대로 정리되어 있는 책을 찾는 방법과 비슷하다고 설명합니다.
인덱스에서는 책의 분류기호 대신에 테이블의 컬럼 값을 사용해 데이터 위치를 검색합니다. 컬럼의 값을 B-Tree 구조체에 입력하고, 루트노드부터 리프노드까지 짧은 액세스 단계를 거쳐 검색 대상 컬럼의 값이 위치한 로우의 위치(Rowid)를 빠르게 찾을 수 있게 됩니다. ( 이 포스팅의 주 목적이 B-Tree가 아닌 관계로 상세한 입력/검색 절차는 생략하겠습니다. )
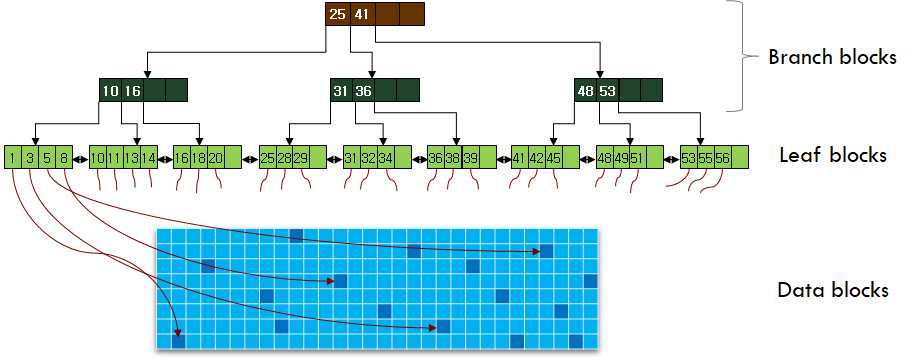
데이터를 빠르게 검색할 수 있는 인덱스, 그렇다고 테이블 하나에 다수의 인덱스를 생성하게 되면 테이블에 데이터 입력/변경/삭제 시 인덱스의 변경 작업량이 증가하여 성능 부하의 원인이 될 수 있습니다.
인덱스를 무조건 많이 생성하는 것보다, 인덱스의 활용도가 높아지도록 조인이나 필터링 조건으로 많이 사용되는 컬럼(흔히 액세스 패턴을 확인한다고 합니다.) 중심으로 인덱스를 생성하는 것이 중요합니다.
즉, 자주 사용되는 쿼리문을 분석한 액세스 패턴 결과를 토대로 인덱스 컬럼을 선정해야 합니다.
인덱스 컬럼을 선정할 때도 단일 컬럼을 선정하는 것보다는 복합 컬럼을 선정하는 것이 성능상 유리합니다. 일반적인 조회 쿼리를 보면 조인이나 필터링 조건에 하나의 컬럼만 사용되는 경우는 극히 드물기 때문입니다. 최대한 인덱스에서 조건에 맞지 않는 로우를 필터링해야만 인덱스에서 rowid를 이용해 테이블에 액세스(Random access)하는 횟수를 줄일 수 있기 때문입니다. 인덱스를 거쳐 테이블의 블럭을 읽은 횟수가 전체 테이블의 블럭 숫자보다 많다면 Full table scan이 더 유리할 것입니다.
그리고 인덱스 컬럼의 순서도 중요합니다. 선행 컬럼의 분포도가 좋다면 인덱스 블록 액세스를 최소화 할 수 있기 때문입니다. 선행 컬럼의 분포도가 좋지 않아서 검색 조건의 값이 여러 리프 노드 블럭에 존재하는 것보다는, 좋은 분포도로 인해 적은 리프 노드 블록에 존재하는 것이 인덱스의 블럭 액세스를 줄이는 방법입니다.
이 외에도 인덱스 스캔 방법 선택도 성능을 위해 고려해야할 사항입니다.
오라클에서 제공하는 인덱스 스캔 방법은 아래와 같습니다.

위 인덱스 스캔 방법에 대해서는 추후에 별도로 포스팅하도록 하겠습니다.
4. 데이터 아키텍처 전략 (Data architecture strategy)
우선 데이터 아키텍처의 정의부터 살펴보겠습니다.
[ dbguide.net ]
데이터아키텍처란 기업의 모든 업무를 데이터 측면에서 처음부터 끝까지 체계화하는 것이다.
데이터아키텍처 전문가란 효과적인 데이터아키텍처 구축을 위해 전사아키텍처와 데이터품질관리에 대한 지식을 바탕으로 데이터 요건분석, 데이터 표준화, 데이터 모델링, 데이터베이스 설계와 이용 등의 직무를 수행하는 실무자를 말한다.
[ wikipedia.org ]
Data architecture is composed of models, policies, rules or standards that govern which data is collected, and how it is stored, arranged, integrated, and put to use in data systems and in organizations.
지극히 학문적인 정의라서 쉽게 가슴에 와닿지는 않을 수도 있습니다.
그럼 위 정의를 기반으로 데이터 아키텍처에서 고려해야 할 항목들을 정리해 보도록 하겠습니다. 제가 지금 생각나는 대로 기술하는 것이기 때문에 아래 항목들이 100% 정답이라고 단정 지을 수는 없습니다.
데이터 요구분석
데이터베이스 선택 (ex : RDBMS, NoSQL, 그래프 DB, 임베디드DB, etc.)
서버/클러스터 구성 (ex: 단일 서버, HA구성, 클러스터 구성, RAC, Max scale, etc.)
파일 시스템 선택 (Oracle : OS Filesystem vs ASM vs Raw device)
데이터베이스 저장 엔진 선택 (MariaDB : Innodb, Aria, XtraDB, etc.)
데이터 표준화 (단어/용어/도메인)
데이터 모델링 (개념/논리/물리, 주제영역)
데이터 간 관계 정의
데이터 인터페이스 정의
데이터 수집 방법 및 범위 (ex : App. 생성 데이터, 외부 연계, 통계 데이터, 시스템 운영 데이터, etc.)
오브젝트 사용 정책 (ex: 트리거 사용 여부, PL/SQL 사용 여부, FK 설정 여부, 최대 인덱스 생성 허용 갯수, etc.)
명명 규칙 (ex: 테이블명, 테이블스페이스명, 인덱스명, 사용자계정명, etc.)
데이터베이스 사용자 계정/권한 정책
데이터베이스 접근 제어 정책
데이터 보관 주기
데이터 로그 관리
데이터 백업 전략
...
위 항목들 외에도 제가 지금 생각하지 못한 데이터 아키텍처 항목들이 더 많을 수도 있습니다.
그리고 위 항목들은 하나의 데이터베이스를 사용한다는 전제하에 List-up을 한 것입니다. 요즘에는 시스템 규모가 커지고 있기 때문에 한 시스템에서도 다양한 데이터베이스를 사용하도록 설계하는 곳도 많습니다.
예를 들어, MariaDB/MySQL의 replication기능으로 데이터를 여러 서버에 복제 해두고 특정 사용자는 특정 서버의 데이터베이스를 액세스 하도록 구성하여 부하가 분산되게 구성할 수 있습니다. 이 때, 사용자가 어떤 서버의 데이터베이스를 사용해야 하는지 알려주는 역할은 동시 접근성이 좋은 오라클이 할 수 있는것입니다.
사용자가 처음 시스템에 접속하면 오라클한테 '어느 서버를 이용하면 되나요?'라고 문의하고, 오라클이 'N번 서버의 데이터베이스를 이용하세요.'라고 응답하면, 그 후로 사용자는 계속 N번 서버의 데이터베이스와 통신을 하게 되는 겁니다.
위의 데이터베이스 구성 방법은 단순한 예시일 뿐입니다. 요즘 MariaDB에서도 MaxScale으로 부하 분산 기능이 강화되었으니 MariaDB만으로도 안정적으로 운영이 가능 할 것입니다.
아무튼, 데이터 아키텍처 설계라는게 단순히 데이터 모델만 그려내는 작업만이 아니라 더 포괄적으로 정책이나 성능 향상을 위한 방법까지도 정의해야 합니다.
본론으로 들어가서, 데이터 아키텍처의 성능 향상 방법, 구체적으로 물리 데이터 모델의 성능 향상 방법에 대해 논의하고자 합니다.
필자가 생각하는 물리 데이터 모델의 성능 향상 방법(의 일부)은 아래와 같습니다.
4-1) Partitioning
데이터베이스에서 파티션은 크기가 큰 테이블이나 인덱스를 관리하기 용이하도록 작은 단위로 쪼개서 저장하는 단위입니다.
한 회사에서 10년간의 거래 내역을 엑셀로 관리하고 있는데, 주로 거래 내역을 입력하고 확인하는건 최근 한달간의 데이터라고 가정해보겠습니다.
만약, 전체 거래 내역이 하나의 엑셀 파일에 저장되어 있다면 어떻게 될까요? 엑셀 파일이 너무 커서 원하는 데이터를 찾는 것도 어려울 것이고, 컴퓨터의 자원을 많이 소비하여 처리 속도도 느려질 것입니다.
이 때, 엑셀 파일을 월 단위로 나눠서 저장하게 되면 어떻게 될까요? 전체 테이터를 저장한 파일에 비해 경량의 엑셀 파일이 될 것입니다. 물론 데이터를 찾고 입력하는 속도도 빨라질 것이고요.
위와 같이 데이터베이스에서 기준에 의해 데이터를 분리하여 저장/관리하는 것이 파티션의 역할입니다.
기준에 의해 데이터가 분리되어 있기 때문에 검색 조건에 기준 컬럼 조건이 포함되어 있다면 전체 테이블 데이터가 아니라 조건에 맞는 파티션 데이터만 액세스(Partition pruning이라고 합니다.)하게 되므로 블록 액세스가 감소됩니다.
아래 예제를 살펴보겠습니다.
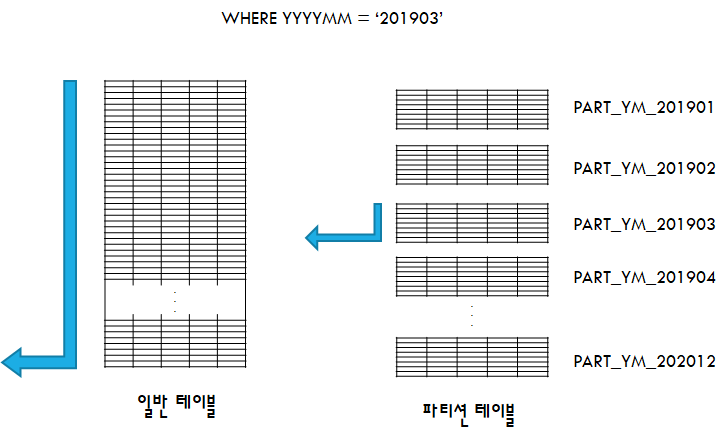
테이블에서 YYYYMM 컬럼 값이 '201903'인 데이터를 조회하는 쿼리를 실행했습니다. 일반 테이블에서 YYYYMM='201903'인 값을 찾기 위해서는 전체 테이블을 탐색해야 합니다.
만약, YYYYMM 컬럼 값을 기준으로 파티션이 된 테이블에서 YYYYMM='201903'인 값을 찾는다면 YYYYMM='201903'에 해당하는 파티션만 탐색하게되므로 블록 액세스가 감소됩니다.
데이터베이스에서 성능 향상을 위한 기본이 블록 액세스를 줄이는 것이니, 파티션을 사용하면 데이터베이스의 성능이 향상 될 수 있게됩니다.
그리고 오라클에서 테이블이나 인덱스를 파티셔닝하게되면 파티션 별로 세그먼트라는 논리적 저장 구조가 분리되어 관리되고, 데이터 파일도 분리(파티션 별 테이블스페이스 설정 작업이 별도로 필요합니다.)되게 됩니다. 물리적으로도 데이터 I/O에 대한 부하가 감소되는 겁니다.
그러나 파티셔닝으로 인해 성능 향상이 기대 된다고 모든 테이블을 파티션 테이블로 생성해야 하는 것은 아닙니다.
크기가 작은 테이블을 파티셔닝하게 되면 관리 포인트가 증가하게 되고, 여러 세그먼트에 분산되어 저장되기 때문에 테이블의 전체 블럭 갯수가 증가할 수 있게 됩니다. 데이터가 대용량이고 기준 조건(파티션 키 컬럼)으로 조회가 빈번한 테이블만 파티션 대상이 됩니다.
만약 파티션 대상 테이블을 선정했다면 테이블 별 파티션 전략도 수립해야 합니다.
아래 목록은 오라클에서 지원하는 파티션의 종류입니다. 데이터 요건과 테이블 액세스 패턴을 고려하여 각 테이블에 적합한 파티션 전략을 선택하면 됩니다.
| 파티션 종류 | 설명 |
| Range Partitioning | 파티션 키 컬럼 값의 범위를 기준으로 파티셔닝을 합니다. 예를들어, DT 컬럼(YYYYMMDD)이 파티션 키 컬럼일 때 'PART_1999' 파티션에는 DT 컬럼 값이 '20000101' 미만인 데이터, 'PART_2000' 파티션에는 DT 컬럼 값이 '20000101' 이상 '20010101' 미만인 데이터, 'PART_2001' 파티션에는 DT 컬럼 값이 '20010101' 이상 '20020101' 미만인 데이터를 저장하게 됩니다. |
| Interval Partitioning | Range 파티셔닝은 파티션을 운영자가 직접 범위를 명시하고 생성해줘야 합니다. 이런 단점을 극복한 것이 Interval 파티셔닝입니다. Range 파티션에서 기존에 생성된 파티션 조건에 맞지 않는 데이터가 입력되면 데이터베이스가 Interval을 기준으로 신규 파티션을 자동으로 만들어주게 됩니다. |
| List Partitioning | 파티션 키 컬럼 값을 기준으로 파티셔닝 합니다. 예를 들어, CODE 컬럼이 파티션 키 컬럼일 때 'PART_A_B' 파티션에는 CODE 컬럼 값이 'A'나 'B'인 데이터, 'PART_C_D' 파티션에는 CODE 컬럼 값이 'C'나 'D'인 데이터를 저장하게 됩니다. |
| Hash Partitioning | 파티션 키 컬럼 값의 해쉬 함수 연산 결과 값을 기준으로 파티셔닝 합니다. |
| Reference Partitioning | 부모 테이블의 파티션 전략을 그대로 상속받게 됩니다. Reference 파티션 테이블에는 부모 테이블에 대한 Foreign Key가 설정되어 있어야 합니다. |
| Composite Partitioning | 파티션 아래에 서브 파티션을 생성하게 됩니다. 서브 파티션은 Range, List, Hash 파티션만 가능합니다. |
인덱스도 파티셔닝에 따라 아래와 같이 구분되어 질 수 있습니다.

| 구분 | 설명 |
| Global Partitioned Index | 테이블의 파티션 전략과는 독립적으로 인덱스만의 파티션 전략으로 파티셔닝된 인덱스 |
| Local Partitioned Index | 테이블의 파티션 전략과 동일하게 파티셔닝된 인덱스 |
| Local Prefixed Index | 테이블 파티션 키 컬럼과 인덱스의 첫 번째 컬럼이 동일한 인덱스 |
| Local Nonprefixed Index | 테이블 파티션 키 컬럼과 인덱스의 첫 번째 컬럼이 상이한 인덱스 |
인덱스 파티션도 테이블 파티션과 마찬가지로 데이터 요건과 테이블 액세스 패턴을 고려하여 각 테이블에 적합한 파티션 전략을 선택해야 합니다.
일반적으로 Local Partitioned Index나 Nonpartitioned Index의 생성 비율이 높은 편이며, Local Nonprefixed Index는 실무에서는 거의 볼 수 없는 구조입니다.
4-2) View와 UDF 사용 최소화 (At least view and UDF)
View는 테이블과는 다르게 별도의 저장 공간이 존재하지 않는 객체입니다. 단지 View 생성 시 정의한 SQL문이 데이터베이스에 저장되어 있으며, 사용자가 뷰를 조회 할 때 마다 저장된 SQL문을 실행하여 결과를 보여주게 됩니다.
View를 사용하게 되면 아래와 같은 장점이 있습니다.
첫 번째, 정보 보안성을 강화할 수 있습니다. 예를 들어, 고객 테이블에서 주민등록번호 등과 같은 개인 정보는 일반 데이터베이스 사용자에게 공개할 수 없다는 보안 정책이 존재할 수 있습니다. 이런 경우 고객 테이블에서 주민등록번호 컬럼을 제외한 나머지 컬럼만 조회하는 View를 생성하고 일반 사용자는 View를 통해 주민등록번호가 제외된 고객 정보를 조회할 수 있도록 처리할 수 있습니다.
두 번째, 쿼리 작성의 복잡도를 줄여줍니다. 아주 복잡한 수식이 사용된 쿼리문이나 길이가 긴 쿼리문을 View로 생성할 수 있습니다. 복잡한 쿼리문 대신에 View를 사용하게 되면 쿼리문이 간결해져서 가독성이 좋아집니다.
물론, View의 단점도 존재합니다.
첫 번째, 관리 포인트가 많아집니다. 너무 많은 View 생성을 남발하게되면 당연히 관리해야할 객체가 증가하게 되어 이 또한 관리 포인트가 됩니다. 더 큰 문제는 View에서 액세스하고 있는 테이블이 변경되면 View에도 영향이 있을 수 있다는 겁니다. View 쿼리문에 직접 명시된 컬럼이 변경 대상이 아니라면 큰 이슈는 없을 것입니다. 하지만, 'SELECT * FROM 테이블명'과 같이 전체 컬럼 조회를 뜻하는 *(Asterisk)를 사용한 경우에는 관련 쿼리문을 수정해야 하는 사태가 발생할수도 있습니다.
두 번째, 성능 부하의 원인이 될 수 있습니다. View 조회 시 데이터 필터링을 위해 WHERE 조건을 사용 할 수 있습니다. 정상적인 경우라면 Optimizer가 View의 Where 조건절도 테이블의 필터링 조건으로 인식하여 인덱스 사용 등의 최적화된 실행 계획을 생성하게 될 것입니다. 하지만 View안의 쿼리가 복잡한 경우 Optimizer는 우선 View를 실행 한 후 마지막에 Where 조건을 필터링하여 결과를 출력할 수도 있습니다. 출력 결과는 1~2건인데 내부적으로는 Full table scan이 발생할 수도 있다는 겁니다.
위와 같은 이유로 필자는 보안을 위한 View외의 무분별한 View 생성은 최소화해야 된다는 원칙을 가지고 있습니다.
UDF(User Defined Function, PL/SQL)도 마찬가지입니다.
복잡한 계산 수식을 절차적으로 해결하기 위해 PL/SQL을 사용하여 UDF을 생성하는 경우가 있습니다. 물론, UDF를 사용하면 쿼리문이 간결해지는 장점이 있습니다.
하지만, UDF는 View처럼 성능 부하를 유발하는 폭탄이 될 수도 있습니다.
SELECT절에 사용된 UDF의 호출 횟수는 데이터 결과 셋의 건수와 동일합니다. 데이터 결과 셋의 건수가 10만건이라면 UDF는 10만번 수행이 되게 됩니다. 수행 횟수가 증가하니 UDF내 쿼리의 실행 횟수도 증가하여 결국 과도한 블럭 액세스를 유발하게 됩니다.
UDF처럼 SELECT절에서 사용되는 서브 쿼리(스칼라 서브 쿼리)의 사용 여부에 따른 블럭 읽기 횟수를 비교해보도록 하겠습니다.
| 튜닝 전 (스칼라 함수 사용) | 튜닝 후 (스칼라 함수 제거) |
| SQL > SELECT S.SALE_DT , S.PROD_NO , (SELECT PROD_NM FROM PROD P WHERE P.PROD_NO = S.PROD_NO) AS PROD_NM FROM PROD_SALE S WHERE S.SALE_DT = '20200301'; |
SQL > SELECT S.SALE_DT , S.PROD_NO , P.PROD_NM FROM PROD_SALE S , PROD P WHERE P.PROD_NO = S.PROD_NO AND S.SALE_DT = '20200301'; |
위의 두 쿼리는 PROD_SALE 테이블에서 SALE_DT 값이 '20200301'인 데이터를 추출하는 쿼리입니다. PROD_SALE 데이터 중 PROD_NO에 매핑되는 PROD_NM 값을 추출하기 위해 PROD 테이블을 액세스 합니다.
왼쪽 튜닝 전의 쿼리에서는 스칼라 서브 쿼리를 이용해 PROD 테이블의 PROD_NM 컬럼 값을 추출합니다.
오른쪽 튜닝 후의 쿼리에서는 PROD 테이블을 조인하여 PROD_NM 컬럼 값을 추출합니다.
위 쿼리의 AUTOTRACE 실행 결과는 아래와 같습니다.

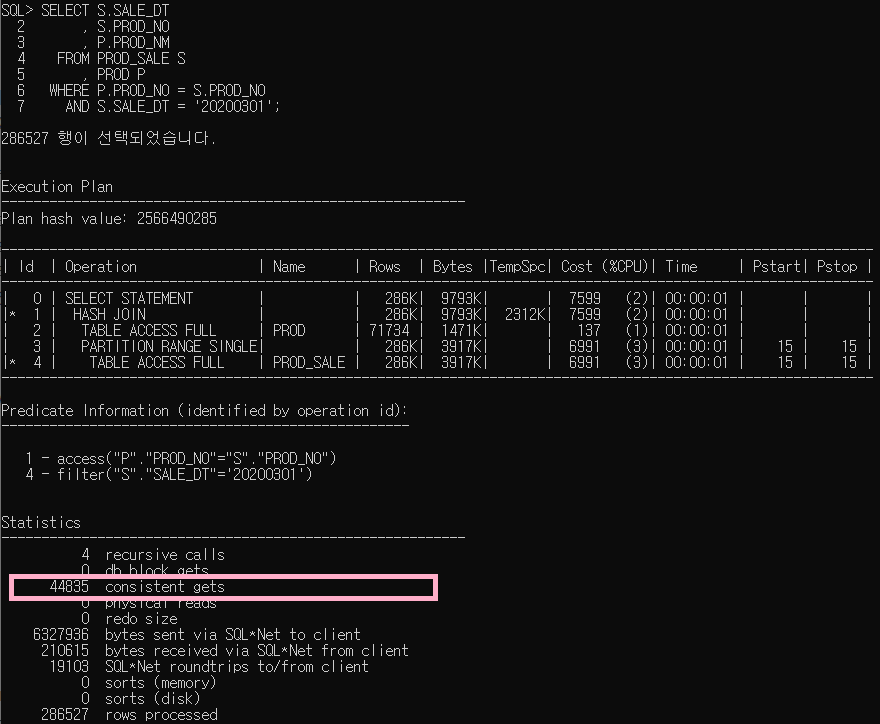
왼쪽 스칼라 서브 쿼리를 사용한 쿼리의 consistent gets 값은 '169,858'입니다.
오른쪽 조인을 사용한 쿼리의 consistent gets 값은 '44,835'입니다.
스칼라 서브 쿼리 사용 시 블럭을 읽은 횟수가 약 4배정도 많은 것을 확인 할 수 있습니다.
위 스칼라 서브 쿼리처럼 SELECT 절에 사용되는 FUNCTION과 PROCEDURE도 마찬가지입니다. 데이터의 출력 결과 건수만큼 실행되게 되어 블럭 읽기가 증가하게 됩니다. 만약, FUNCTION이나 PROCEDURE 내 쿼리에서 Full table scan이 발생한다면 데이터 건수만큼 Full table scan이 발생하게 됩니다. 심각한 성능 저하의 원인이 되는거죠.
이 문제를 해결하는 방법은 위 스칼라 서브쿼리처럼 FUNCTION과 PROCEDURE을 제거입니다.
구체적인 예제는 아래 포스트를 참고하시면 됩니다.
Oracle SQL 튜닝 예제 #2 - PL/SQL 제거
비효율적인 PL/SQL(Function)을 제거하여 성능을 높인 쿼리 예제를 살펴보도록 하겠습니다. 이 포스트에 사용된 예제는 부하를 유발하는 PL/SQL를 보여주기 위해 임의로 작성된 쿼리입니다. 최대한 가독성을 높이..
sparkdia.tistory.com
4-3) 데이터 모델 변경(Change data model)
데이터 모델 설계가 중요한 이유 중의 하나는 설계가 완료된 이후에는 변경이 어렵다는 점입니다.
건축 설계를 예를 들어보겠습니다. 높은 빌딩이 완공되어 완공식을 하는데, 건물주가 1층 로비의 천장이 너무 낮다는 의견을 내놓았습니다. 완공된 건물의 1층 로비 천장을 높이기 위해 2층 바닥을 뚫기라도 해야 한다는 건가요? 절대 불가능한 일인 것입니다.
데이터 모델도 마찬가지입니다. 오픈된 시스템의 설계 오류를 발견하더라도 큰 구조의 변경은 쉽지 않은게 현실입니다. 더군다나 24시간 365일 서비스를 하는 시스템이라면 더더욱 힘든 일이죠.
그래도 성능 이슈를 해결하기 위해 어쩔수 없이 데이터 모델을 변경을 선택해야 하는 경우도 발생합니다.
집계성 테이블의 경우는 데이터 모델 관점에서는 데이터 중복에 해당되므로 설계 시 최대한 생성을 배제해야 할 대상입니다. 하지만, OLTP시스템에서도 월 판매 현황 같은 집계성 데이터를 자주 조회하는 경우도 존재합니다. 이런 요건이 있다면 데이터가 중복이더라도 데이터베이스 성능을 위해 집계 테이블을 생성하는 것을 고려할 수 있습니다. 집계 테이블을 생성하고 데이터베이스 사용량이 적은 새벽 시간에 배치를 수행하면 사용량이 많은 peek 시간에 데이터 집계 쿼리로 인한 부하를 피할 수 있게 됩니다.
그리고 거래 내역 등 크기가 큰 테이블에 파티션이 적용되지 않았거나 파티션 키가 잘못 정의된 경우도 조심스럽게 모델 변경을 고려 할 수도 있습니다.
이런 규모의 테이블은 시스템 내에서 활용도가 높을 수 있으므로, 단순한 테이블 변경으로 작업을 마무리 할 수는 없을 것입니다.
테이블이 변경되면 테이블과 관련된 SQL의 모든 실행 계획이 변경될 가능성이 큽니다. 어제까지만해도 잘 수행되던 쿼리가 테이블 변경으로 순식간에 악성쿼리로 변경될 가능성이 있기 때문입니다.
또한 기존의 데이터도 유지해야 하므로 이전 테이블에서 변경된 테이블로 데이터를 이관하는 작업도 필요합니다.
따라서, 이러한 대용량의 테이블의 구조를 변경하기 위해서는 사전 작업이 필요합니다. 우선 임시 테이블에 데이터를 적재하여 쿼리 테스트를 진행해야 합니다. 기존의 쿼리를 테스트하여 실행 계획 상에 문제가 없는지 확인이 필요합니다. 쿼리상의 문제가 없음이 확인된 후에야 현행 데이터 이관까지 포함된 테이블 변경작업을 진행할 수 있습니다. 추가로 테이블 통계 정보를 생성하거나 기존 테이블에서 데이터를 이관하는 것도 잊지 말아야 합니다.
5. SQL 튜닝 (SQL tuning)
운영중인 데이터베이스에서 성능 저하가 발생하였을 때, 성능 최적화를 위해 선택할 수 있는 가장 큰 대안은 SQL 튜닝일 것입니다. 위에서 언급한 것처럼 운영 중인 시스템의 모델을 변경하거나 인덱스를 추가/변경하는 작업은 영향도가 큰 작업이므로 실제로 적용할 수 있는 기회는 많지 않습니다.
SQL을 튜닝하는 구체적인 방법은 아래와 같습니다.
1) Use hint
옵티마이저가 항상 최적의 실행 계획을 제시하는 것은 아닙니다. 조인 대상 데이터 건수가 적은데 NL조인이 아닌 Hash 조인을 수행하거나, 엉뚱한 인덱스를 액세스하는 실행 계획이 수립 될 수도 있습니다.
이런 경우 SQL에 힌트를 사용하여 쿼리의 실행계획을 변경할 수 있습니다.
오라클에서 제공하는 주요 힌트는 아래와 같습니다.
| 힌트 | 설명 |
| USE_NL(테이블) | Nested Loops 조인을 유도합니다. |
| USE_HASH(테이블) | Hash 조인을 유도합니다. |
| USE_MERGE(테이블) | Sort Merge 조인을 유도합니다. |
| ORDERED | FROM에 명시된 테이블을 순서대로 액세스하도록 유도합니다. |
| LEADING(테이블) | 명시된 테이블부터 액세스하도록 유도합니다. |
| INDEX(테이블 인덱스명) | 테이블 액세스 시 지정 인덱스를 이용하도록 유도합니다. |
| NO_INDEX(테이블 인덱스명) | 테이블 엑세스 시 지정 인덱스를 제외하도록 유도합니다. |
| FULL(테이블) | 테이블 액세스 시 Full table scan을 유도합니다. |
| INDEX_RS(테이블 인덱스명) | Index Range Scan을 유도합니다. |
| INDEX_SS(테이블 인덱스명) | Index Skip Scan을 유도합니다. |
| INDEX_FFS(테이블 인덱스명) | Index Fast Full Scan을 유도합니다. |
| UNNEST | 서브 쿼리와 메인 쿼리를 합쳐 조인을 수행하도록 유도합니다. |
| NO_UNNEST | 서브 쿼리를 유지한 상태에서 필터 방식으로 처리하도록 유도합니다. |
| MERGE | 인라인 뷰를 풀어 메인 쿼리내 테이블과 조인으로 수행되도록 유도합니다. |
| NO_MERGE | 뷰를 Merge하지 않고 인라인 뷰가 그대로 유지도록 유도합니다. |
| PARALLEL |
쿼리를 병렬로 수행하도록 유도합니다. |
2) Rewrite SQL
누누히 얘기하지만 SQL의 성능 판단 기준은 실행 시간과 블럭 액세스 횟수입니다.
위 기준으로 악성 쿼리를 검출해보면 데이터를 절차적으로 처리하도록 작성된 쿼리를 발견하기도 합니다. 동일한 테이블을 여러 번 액세스하거나, 데이터를 줄일 수 있는 부분을 놓치고 있는 경우가 있는거죠. 물론 개발 시간이 촉박한 상황에서는 절차적인 방식으로 쿼리를 작성하고 쿼리 수행 결과가 정상이면 바로 쿼리 작성을 완료하고 넘어가는 일이 비일비재하다는 것을 알고 있습니다. 이러한 상황적 한계로 SQL 튜너가 별도로 필요한 것이고요.
아무튼 SQL 쿼리문은 집합적인 사고로 데이터 액세스를 최소화 할 수 있는 방법을 사용해 작성되어야 합니다. 절차적으로 작성된 쿼리문은 최대한 집합적 관점에서 다시 재작성이 필요합니다.

SQL 튜닝 예제는 아래 포스트를 참고 바랍니다.
Oracle SQL 튜닝 예제 #1 - 집합적 사고 접근법
[ 튜닝 전 ] 아래 쿼리를 살펴보도록 하겠습니다. SELECT CNT1, CNT2, CNT3, CNT4, CNT5, CNT6, CNT7, CNT8 FROM ( SELECT (SELECT COUNT(*) FROM CHG_LOGS WHERE REG_DT=:B1 AND ST_CD='0' AND LOG_LVL='1') CNT..
sparkdia.tistory.com
3) Remove UDF
위 4-2) View와 UDF 사용 최소화 (At least view and UDF)에서 언급했듯이 UDF는 쿼리문을 간결하게 만들어주지만, 잘못 사용되면 성능 부하의 큰 원인이 됩니다. UDF사용으로 성능 부하를 일으키는 SQL문은 당연히 해당 UDF를 제거하는 작업을 해야 합니다.
구체적인 UDF 제거 방법은 위 "4-2) View와 UDF 사용 최소화 (At least view and UDF)"에서 링크한 포스트를 참고 바랍니다.
감사합니다.
'Database' 카테고리의 다른 글
| 테이블 조인 종류(Table Join Type) (0) | 2020.03.29 |
|---|---|
| SQL tuning 작업은 이제 불필요하다? (0) | 2020.03.16 |
| Cassandra cqlsh 기본 사용법 (0) | 2016.02.11 |
| Cassandra 설치 2 (0) | 2016.02.11 |
| Cassandra 설치 1 - 사전 작업 (JDK, Python) (0) | 2016.02.11 |