테이블 조인 방식은 테이블의 각 로우를 매핑 시 어떤 메커니즘을 사용하느냐에 따라 조인을 구분하는 겁니다.
데이터 셋의 건수 등을 기반으로 옵티마이져가 적합한 조인 메커니즘을 선택하여 실행 계획을 생성하게 됩니다. 이때, 테이블 통계정보의 오류 등으로 인하여 적합하지 않은 조인 방식이 선택될 수도 있습니다. 잘못 선택된 조인 방식은 때때로 성능상의 부하를 유발하게 됩니다.
따라서, 각 조인 방식에 대한 메카니즘을 파악하여 조회 쿼리에 적합한 조인 방식이 선택되도록 유도하는 것이 데이터베이스 성능 향상을 위한 중요한 방법 중의 하나가 되겠습니다.
오라클에서 제공하는 조인 방식(Join methods)은 아래와 같습니다.

1. NL(Nested Loops) 조인
Nested Loops 조인(이하 NL 조인)을 한국어로 직역하면 '중첩 반복 조인'입니다. 뜻 그대로 거듭된 반복 작업으로 조인을 수행하는 방식이 바로 NL 조인입니다.
NL 조인은 드라이빙 테이블*의 한 로우와 매칭되는 드리븐 테이블**내 로우를 찾기위해 드리븐 테이블의 모든 데이터를 탐색하고 조인 컬럼 값이 일치하는 경우 양쪽 테이블의 두 로우를 연결합니다. 드라이빙 테이블에서 조회 조건에 부합하는 로우가 여러 건인 경우에는 로우 수만큼 위 작업을 반복적으로 수행하여 조인을 완료하게 됩니다.
* 드라이빙 테이블(Driving table) : 조인 대상 테이블 중 먼저 액세스하는 테이블을 말하며 Outer table이라고도 표현 가능합니다.
** 드리븐 테이블(Driven-to table) : 조인 대상 테이블 중 나중에 액세스하는 테이블을 말하며 Inner table이라고도 표현 가능합니다.
1.1. NL 조인 작동 방식
오라클 문서에서 슈도(pseudo) 코드로 표현한 NL 조인 로직은 아래와 같습니다. NL 조인과 중첩된 For loop 수행이 개념적으로 동일한 로직이라고 설명하고 있습니다.

우선 드라이빙 테이블(위 로직에서는 employees 테이블)에서 조건에 맞는 (where X=Y) 로우를 (바깥쪽, Outer) For문을 이용해 모두 추출하게 됩니다. 이때, 드라이빙 테이블에서 로우가 추출될 때마다 (안쪽, Inner) For문을 수행하게 됩니다. For문을 수행하면서 드리븐 테이블(위 로직에서는 departments 테이블)의 로우를 탐색하는데, 드라이빙 테이블의 조인 컬럼 값과 매칭 된다면 output에 조인 결과를 저장하게 됩니다.
위 로직을 그림으로 표현하면 아래와 같습니다.

위에서 설명했듯이 NL 조인은 드라이빙 테이블에서 추출되는 데이터 건수만큼 드리븐 테이블을 반복해서 탐색하게 됩니다. 드라이빙 테이블에서 10건의 로우가 추출되면 드리븐 테이블을 10번 반복해서 액세스를 하게되고, 10만 건의 로우가 추출되면 드리븐 테이블을 10만 번 반복해서 액세스를 하게 됩니다.
이와 같은 NL 조인의 특성 때문에 아래 조건을 충족해야만 NL 조인 시 좋은 성능을 보장 받을 수 있습니다.
1) 조인 테이블 중 추출 건수가 적은 테이블을 드라이빙 테이블로 선정.
드라이빙 테이블의 추출 건수가 곧 드리븐 테이블의 액세스 반복 횟수가 되므로 건수가 더 적은 테이블이 드라이빙 테이블로 선정되어야 합니다.
2) 드리븐 테이블에 조인 조건 컬럼으로 구성된 인덱스가 존재.
드리븐 테이블은 드라이빙 테이블의 추출 건수만큼 반복해서 액세스하게 됩니다. 이때 조인 컬럼으로 구성된 인덱스가 존재한다면 드리븐 테이블의 모든 데이터를 액세스 하지 않아도 인덱스를 이용해 조인 조건에 맞는 로우를 추출할 수 있게 됩니다. 만약 조인 컬럼으로 구성된 인덱스가 존재하지 않는다면 Full table scan이 반복적으로 발생하여 성능상 이슈가 발생할 수 있습니다.
1.2. NL 조인 실행 계획
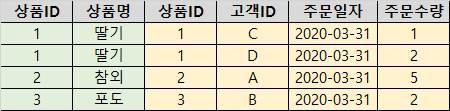
아래 쿼리는 EMPLOYEES 테이블과 DEPARTMENTS 테이블을 조인하는 쿼리 예제입니다.
두 테이블의 조인 컬럼은 DEPARTMENT_ID이며, EMPOLYEES 테이블의 LAST_NAME이 'A'로 시작하는 데이터만 추출하고자 합니다.
EMPLOYEES 테이블에서 LAST_NAME이 'A'로 시작하는 데이터는 4건이며, DEPARTMENTS 테이블의 데이터 건수는 27건입니다.
SELECT E.EMPLOYEE_ID
, E.FIRST_NAME
, E.LAST_NAME
, D.DEPARTMENT_NAME
FROM EMPLOYEES E
, DEPARTMENTS D
WHERE E.DEPARTMENT_ID = D.DEPARTMENT_ID
AND E.LAST_NAME LIKE 'A%' ;위 쿼리의 실행 계획은 아래와 같습니다.

1) 1차 Nested Loops ( Id = 2 )
1-1) EMP_NAME_IX 인덱스를 탐색하여 "E.LAST_NAME LIKE 'A%'" 조건에 부합하는 rowid를 취득합니다. (Id = 4)
1-2) 1-1)에서 얻은 rowid로 EMPLOYEES 테이블을 액세스하여 EMPLOYEE_ID와 DEPARTMENT_ID값을 취득합니다. (Id = 3)
1-3) 1-2)의 데이터가 NL조인의 Outer가 됩니다. For문처럼 Outer의 로우를 하나씩 인출하여 DEPT_ID_PK 인덱스를 탐색하고 DEPATMENT_ID 값과 매칭 되는 rowid를 취득합니다. EMPLOYEES 테이블과 DEPARTMENTS 테이블의 인덱스와 NL조인을 하게 됩니다. (id = 5,1)
2) 2차 Nested Loops ( Id = 1 )
2-1) 1-3)의 데이터가 NL 조인의 Outer가 됩니다. For문처럼 Outer의 로우를 하나씩 인출하여 rowid로 DEPARTMENTS 테이블에 액세스하여 DEPARTMENT_NAME 값을 취득합니다. (Id = 6,1)
2. 해시(Hash) 조인
해시 조인은 조인 키 컬럼 값의 해시 함수 결과를 이용하여 조인하는 방식입니다. NL 조인과는 상대적으로 큰 데이터 셋을 조인하기 위한 방식입니다.
2.1. Hash 조인 작동 방식
해시 조인에서도 조인 대상 테이블 중 크기가 더 작은 테이블부터 액세스 합니다.
해시 조인에서는 먼저 액세스 하는 테이블을 빌드(Build) 테이블, 나중에 액세스 하는 테이블은 프로브(Probe) 테이블이라고 부릅니다.
① 빌드 테이블을 읽어 각 로우의 조인 키 컬럼 값을 해시 함수에 대입합니다.
② 해시 함수의 결과 값을 이용해 메모리(PGA)에 해시 테이블을 생성합니다. 해시 함수 결과 값은 해시 테이블에서 각 로우가 저장된 슬롯의 위치를 나타냅니다. 만약, 조인 키 컬럼 값이 상이하지만 동일한 해시 함수 결과 값이 나온 로우는 동일한 슬롯(Slot)에 저장되며 각 데이터는 링크드 리스트로 연결됩니다.

③ 빌드 테이블의 모든 로우가 해시 테이블에 저장이 완료되면, 프로브 테이블의 데이터를 한 로우씩 읽기 시작합니다. 프로브 테이블도 빌드 테이블과 마찬가지로 조인 키 컬럼 값을 ②에서 사용된 동일한 해시 함수에 입력하여 결과 값을 계산합니다.
④ 계산된 해시 함수 결과 값을 이용해 해시 테이블 내 관련된(해시 결과 값이 동일한) 슬롯을 찾아갑니다. 만약, 해시 결과 값이 동일한 슬롯이 없다면 조인에 실패한 로우이므로 프로브 테이블의 다음 로우를 읽어 조인 연산을 계속 진행합니다.
⑤ 해시 결과 값으로 관련 슬롯을 찾았으면 슬롯 안에 저장된 빌드 테이블의 로우를 확인합니다. 로우의 조인 컬럼 값이 프로브 테이블 로우의 조인 컬럼 값과 일치하면 두 로우를 매핑하여 결과 셋(Result set)에 저장합니다. 슬롯 내에는 동일한 조인 컬럼 값을 가진 로우가 여러 건 존재할 수 있으므로 슬롯 내 링크드 리스트를 끝까지 탐색하여 조인을 완료합니다.
해시 조인에서는 아래 조건을 충족하는 경우 좋은 성능을 보장 받을 수 있습니다.
1) 조인 테이블 중 추출 건수가 적은 테이블을 빌드 테이블로 선정.
조인을 위해 빌드 테이블의 데이터는 PGA 메모리의 해시 테이블에 저장됩니다. 해시 테이블의 크기가 커서 PGA 메모리가 부족해지면 가상 메모리를 사용하기 떄문에 DISK I/O가 발생하게 됩니다. 따라서, 데이터 건수가 적은 테이블이 빌드 테이블로 선정되어야 하며, 쿼리문 상에 결과 셋에 저장될 컬럼명만 명시하여 해시 테이블의 크기를 최소화해야 합니다.
2) 프로브 테이블은 Full table scan이 유리.
일반적으로 해시 조인에서 프로브 테이블은 대용량의 테이블입니다. 만약 인덱스를 이용해 프로브 테이블을 액세스하면 테이블 랜덤 액세스가 과도하게 발생하여 블록 I/O가 증가하게 됩니다. 테이블 액세스 없이 INDEX SCAN만으로 데이터 추출이 가능한 경우는 제외하고, 되도록이면 인덱스 스캔 없이 테이블만 스캔하여 블럭 I/O를 줄여야 합니다.
참고로, 오라클 문서에서 슈도(pseudo) 코드로 표현한 해시 조인 로직은 아래와 같습니다.


2.2. Hash 조인 실행 계획
아래 쿼리는 PROD 테이블과 PROD_SALE 테이블을 조인하는 쿼리 예제이며, 조인 컬럼은 PROD_NO입니다. PROD 테이블의 전체 테이블 건수는 71,734건입니다. PROD_SALE 테이블은 SALE_DT 컬럼으로 파티셔닝 되어 있으며, SALE_DT = '20191231'인 데이터 건수는 287,290건으로 대용량 테이블입니다.
SELECT S.SALE_DT
, P.PROD_NM
, S.PROD_QTY
FROM PROD P
, PROD_SALE S
WHERE P.PROD_NO = S.PROD_NO
AND S.SALE_DT = '20191231' ;위 쿼리의 실행 계획은 아래와 같습니다.

1) 두 테이블 중에서 크기가 작은 PROD 테이블이 빌드 테이블이 되며, FULL TABLE SCAN을 하게 됩니다. PROD 테이블의 각 ROW를 읽으면서 조인 칼럼의 값인 PROD_NO 값을 해시 함수에 대입한 결과 값으로 해시 테이블을 메모리에 생성합니다. (Id = 2)
2) 해시 테이블 생성이 완료되면 프로브 테이블인 PROD_SALE 테이블을 FULL TABLE SCAN하기 시작합니다.(Id = 4) PROD_SALE 테이블은Where 절의 파티션 컬럼 필터링 조건으로 인하여 하나의 파티션만 액세스 하게 됩니다.(Id = 3)
3) PROD_SALE 테이블의 로우를 하나씩 읽으면서 조인 컬럼 값인 PROD_NO 값을 해시 함수에 대입한 결과 값으로 해시 테이블 내 관련 슬롯을 찾아가게 됩니다. 슬롯에 저장된 빌드 테이블의 데이터와 조인 키 칼럼 값을 비교하면서 컬럼 값이 일치하는 데이터와 매핑하여 조인을 완료하게 됩니다. (Id = 1)
3. 소트 머지(Sort Merge) 조인
소트 머지 조인은 조인 대상 테이블 데이터의 조인 키 컬럼 값을 기준으로 각 데이터 셋을 정렬한 후 작은 값부터 양쪽의 조인 키 컬럼 값이 매칭 되는지 확인하여 조인하는 방법입니다.

오라클의 옵티마이저는 조인 조건이 동등 조건(=)이 아니거나(해시 조인은 동등 조건만 가능) 인덱스 사용으로 정렬 작업을 생략 할 수 있는 경우에 해시 조인 대신 소트 머지 조인을 선택합니다.
또한, 해시 조인에서 해시 테이블이 너무 커서 PGA 메모리 부족으로 가상 메모리(디스크)를 사용하게 되면 디스크 I/O가 빈번하게 발생하게 됩니다. 프로브 테이블의 조인 키 칼럼 값은 정렬된 상태가 아니기 때문에 해시 테이블의 블록을 여러 번 읽어야 할 수도 있습니다. 하지만 소트 머지 조인은 조인 키 컬럼 값이 정렬된 상태이기 때문에 가상 디스크를 사용하더라도 디스크 I/O 횟수가 해시에 비해 훨씬 적다는 장점이 있습니다.
3.1. Sort Merge조인 작동 방식
소트 머지 조인을 수행하기 위해서 각 조인 대상 테이블은 조인 키 컬럼 기준으로 정렬되어 메모리(PGA)에 저장됩니다.
정렬된 첫 번째 데이터 셋에서 첫 번째 로우를 읽어 조인 키 컬럼 값이 두 번째 데이터 셋에 존재하는지 확인합니다.
만약, 매칭되는 조인 키 컬럼 값이 두 번째 데이터 셋에 존재하지 않는다면 첫 번째 데이터 셋을 순차적으로 읽어 먼저 읽은 로우의 칼럼 값 보다 큰 로우의 컬럼 값을 찾습니다.

위 그림에서 첫 번째 데이터 셋의 '10'은 두 번째 데이터 셋의 첫 번째 값인 '20'보다 작은 값이므로 매칭되는 로우가 없으므로 첫 번째 데이터 셋의 '10' 다음의 값인 '20'을 읽게 됩니다.

두 번째 테이블에서 아직 탐색이 진행되지 않았으므로 첫 번째 컬럼 값부터 데이터를 읽습니다. 이 값이 첫 번째 데이터 셋에서 읽은 값 '20'과 동일하다면 해당 값보다 큰 데이터가 나올 때까지 두 번째 데이터 셋을 읽어 나가면서 매칭 된 데이터를 결과 셋에 저장하게 됩니다.
두 번째 테이블에서 '20'보다 큰 값을 발견하면 해당 로우의 위치를 기억해놓고 첫 번째 테이블로 돌아가 다음 로우를 읽습니다. 로우 값 '30'을 읽어 두 번째 테이블에서 마지막 탐색 위치의 값과 비교합니다. 두 번째 테이블의 값도 '30'이므로 두 데이터를 결과 셋에 저장합니다. 마찬가지로 두 번째 테이블에서의 탐색을 계속 진행하는데 다음 로우의 값은 '30'보다 크므로 탐색을 중지하고 다시 첫 번째 데이터셋으로 돌아가 다음 로우를 읽습니다.

첫 번째 데이터 셋의 다음 로우의 값 '40'은 두 번째 데이터 셋의 마지막 탐색 로우의 값인 '50'보다 작으므로 매칭 되는 로우가 없는 것입니다.
다시 첫 번째 데이터 셋의 다음 로우인 '50'을 읽습니다. 두 번째 데이터 셋의 마지막 탐색 로우의 값인 '50'과 동일하므로 두 번째 데이터 셋을 계속 탐색하면서 매칭되는 데이터를 결과 셋에 저장하게 됩니다.
두 데이터 셋의 탐색이 종료되면 조인 작업이 완료된 것입니다.
참고로, 오라클 문서에서 슈도(pseudo) 코드로 표현한 소트 머지 조인 로직은 아래와 같습니다.

3.2. Sort Merge조인 실행 계획
아래 쿼리는 EMPLOYEES 테이블과 DEPARTMENTS 테이블을 DEPARTMENT_ID 조인 키 컬럼 기준으로 조인하는 쿼리 예제입니다. 두 테이블을 인덱스 사용 없이 Full table scan을 하기 위해 NO_INDEX 힌트를 사용하였으며, 소트 머지 조인을 하기 위해 USE_MERGE 힌트를 사용하였습니다.
SELECT /*+ USE_MERGE(d e) NO_INDEX(e) NO_INDEX(d) */
D.DEPARTMENT_NAME
, E.FIRST_NAME
, E.LAST_NAME
FROM EMPLOYEES E
, DEPARTMENTS D
WHERE E.DEPARTMENT_ID = D.DEPARTMENT_ID ;위 쿼리의 실행 계획은 아래와 같습니다.

1) 첫 번째 테이블 DEPARTMENTS 테이블을 Full table scan 하여 조인 키 컬럼 기준으로 정렬하는 Sort join 작업을 진행합니다. ( Id = 3,2 )
2) 두 번째 테이블 EMPLOYEES 테이블도 Full table scan하여 조인 키 컬럼 기준으로 정렬하는 Sort join 작업을 진행합니다. ( Id = 5,4 )
3) 정렬된 키 컬럼 값을 순차적으로 읽어 두 테이블 양쪽 모두에 조인 컬럼 키 값이 존재하면 매핑하여 데이터 결과 셋에 추가합니다. ( Id = 1 )
이상으로 조인 방식에 대해 설명드렸습니다.
참고로 데이터베이스에서 조인을 구분하는 방법은 위에서 언급한 조인 방식 외에 조인 종류도 존재합니다.
우리가 쿼리 작성 시 사용하는 Inner join, Outer join 등의 문법으로 구분하는 조인 방법입니다. (깊게 살펴보면 한 쪽 테이블에만 존재하는 데이터 출력 방법이라고 설명할 수 있습니다.)
조인 종류에 대해서는 아래 포스트를 참고하시면 됩니다.
테이블 조인 종류(Table Join Type)
데이터베이스에서 데이터는 다수의 테이블에 나뉘어 저장되어 있습니다. 데이터의 중복을 제거하고 무결성을 보장하기 위해서 데이터 성격에 따라 분류하여 테이블에 저장을 하는 겁니다. 이렇게 테이블별로 분리..
sparkdia.tistory.com
'Database > Oracle' 카테고리의 다른 글
| Oracle SQL 튜닝 예제 #2 - PL/SQL 제거 (1) | 2020.04.19 |
|---|---|
| Oracle SQL 튜닝 예제 #1 - 집합적 사고 접근법 (0) | 2020.04.11 |
| 오라클(Oracle) 19c 설치 (Windows 10환경) (3) | 2020.03.27 |