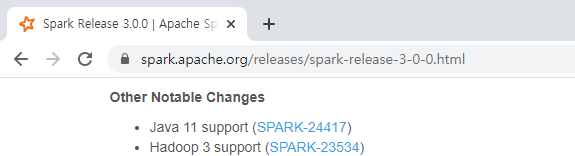
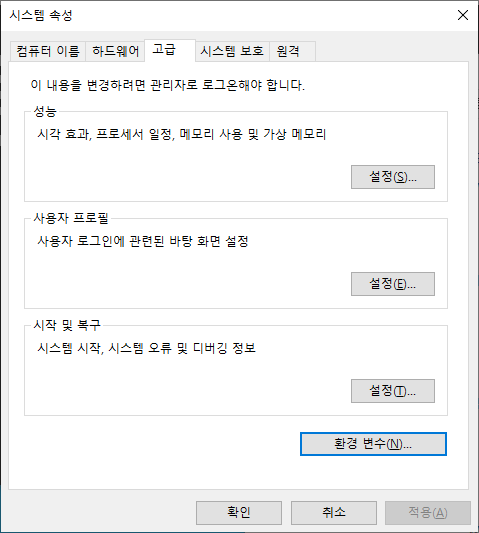
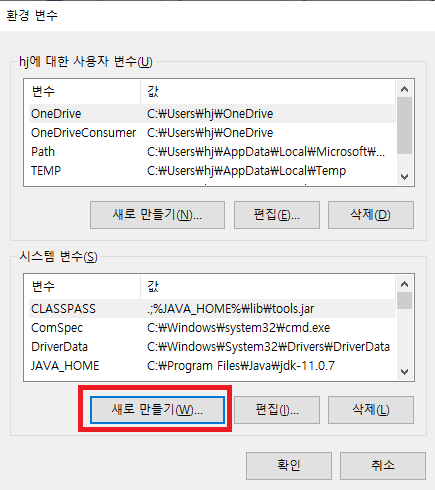
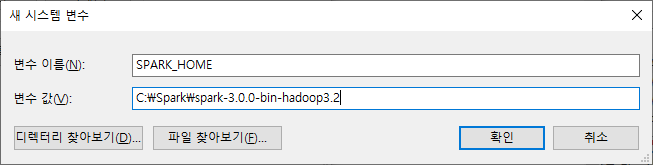
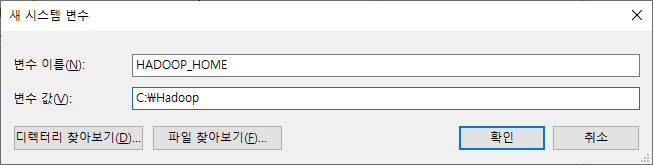
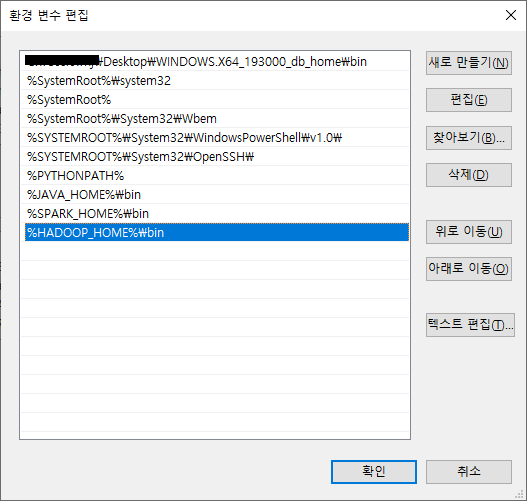
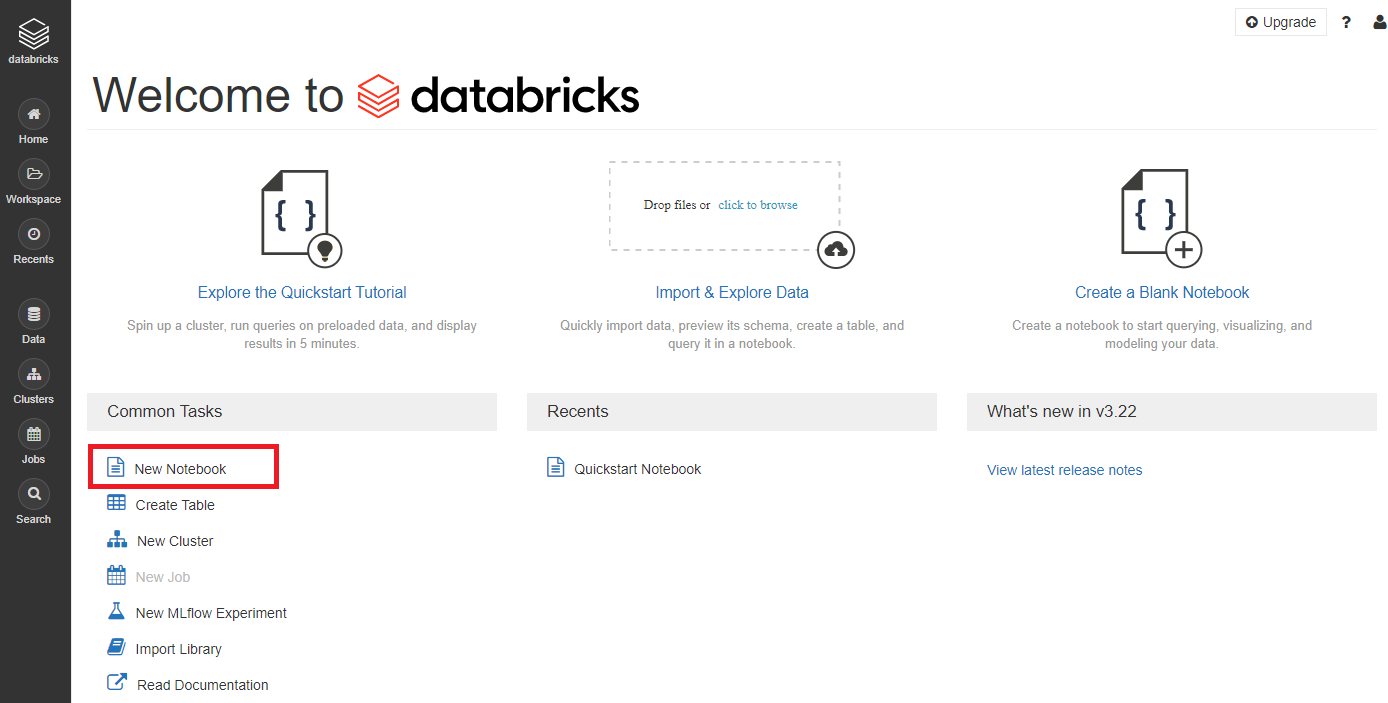
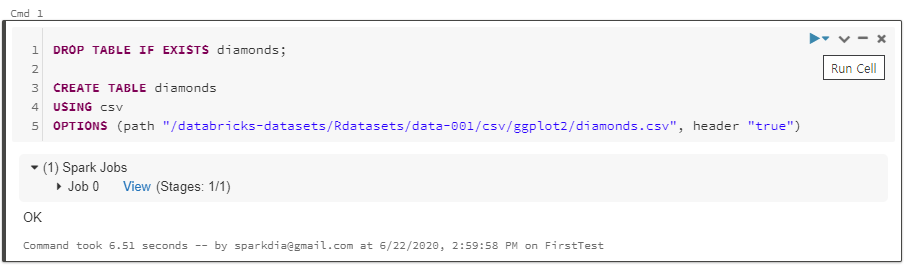
윈도우 10 환경에서 PostgreSQL 12 버전을 설치해보도록 하겠습니다.
이 포스트를 작성하는 시점에 PostgreSQL 13 Beta 2 버전이 릴리즈(2020. 06.25)되었는데요. 아직은 베타 버전이므로 안정성을 생각해서 하위 버전인 12 버전을 다운로드 받아 설치하겠습니다.
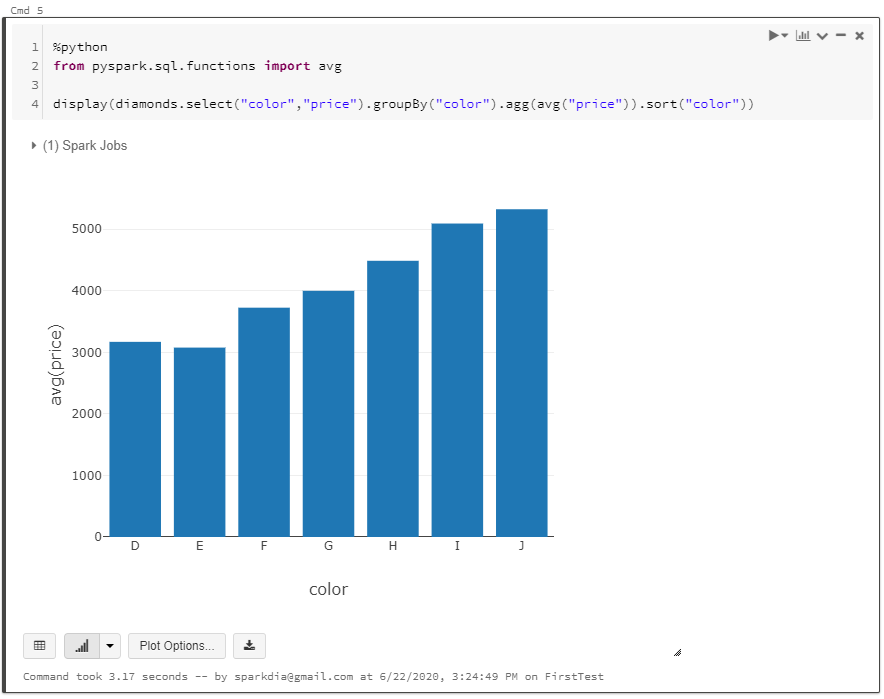
1. 설치 파일 다운로드
* URL : https://www.enterprisedb.com/downloads/postgres-postgresql-downloads
PostgreSQL Database Download
Please Note: EDB no longer provides Linux installers for PostgreSQL 11 and later versions, and users are encouraged to use the platform-native packages. Version 10.x and below will be supported until their end of life.
www.enterprisedb.com
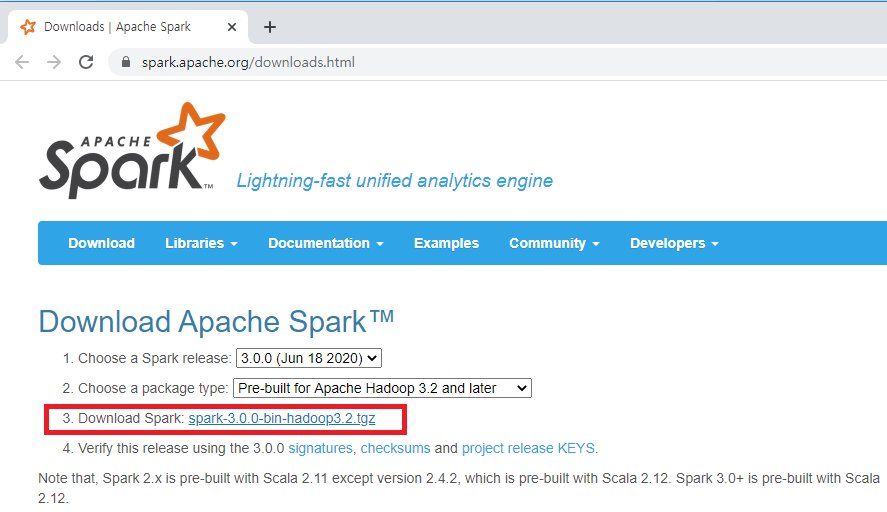
위 URL에 접속하면 아래와 같은 다운로드 페이지를 확인하실 수 있습니다.
아래 페이지에서 12.3 버전, WIndows x86-64의 'Download' 버튼을 클릭하면 설치 파일을 다운로드 받을 수 있습니다.
만약, 소스 빌드를 통해 PostgreSQL을 설치하거나, 전문가용 설치 파일을 다운로드 하고자하는 경우에는 하단의 URL에 접속하여 파일을 다운로드 하셔야 합니다.
> URL : https://www.postgresql.org/download/
2. PostgreSQL 설치
다운로드가 완료된 설치 파일을 실행합니다.
설치 파일을 실행하면 아래와 같이 Welcome 메세지를 확인하실 수 있습니다.

'Next' 버튼을 클릭하여 다음 단계로 넘어갑니다.
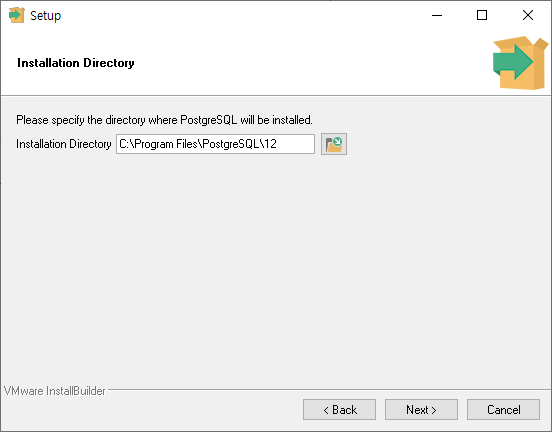
PostgreSQL을 설치할 경로를 입력 후 'Next' 버튼을 클릭합니다.
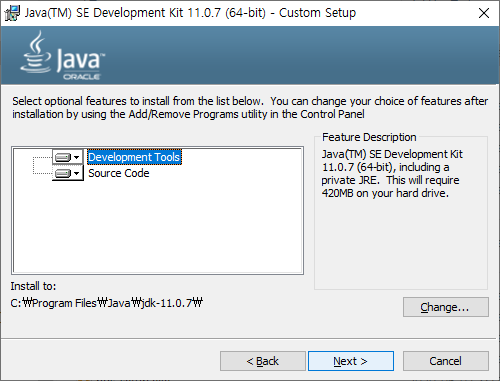
설치할 컴포넌트를 선택하는 화면입니다.
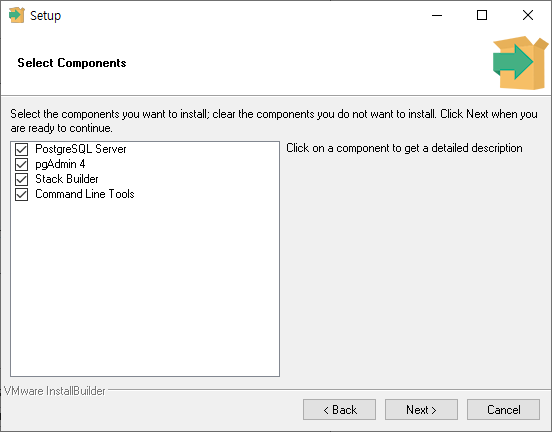
PostgreSQL 서버 외에 아래 추가적인 컴포넌트를 설치할 수 있습니다.
- pgAdmin : 데이터베이스를 관리하고 개발하기 위한 그래픽 기반 툴.
- Stack Builder : 추가로 설치해서 사용 가능한 툴과 드라이버를 관리하는 패키지 매니저.
예) 관리, 통합, 마이그레이션, 복제, 공간 연산, 커넥터 등.
- Command Line Tools : SQL Shell (psql)
설치할 컴포넌트 선택이 완료되면 'Next' 버튼을 클릭합니다.
데이터 파일을 저장할 경로를 설정 후 'Next' 버튼을 클릭합니다.
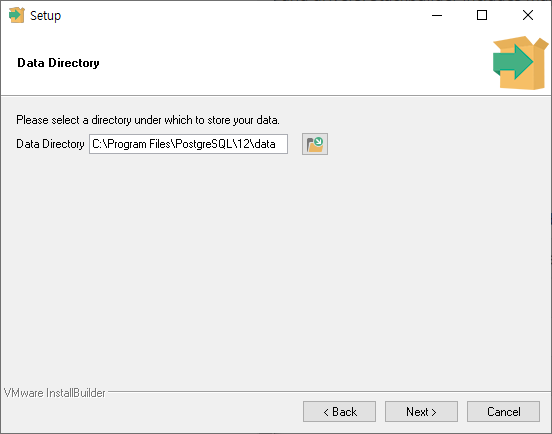
데이터베이스 Superuser 계정의 비밀번호와 비밀번호 확인 값을 입력 후 'Next' 버튼을 클릭합니다.
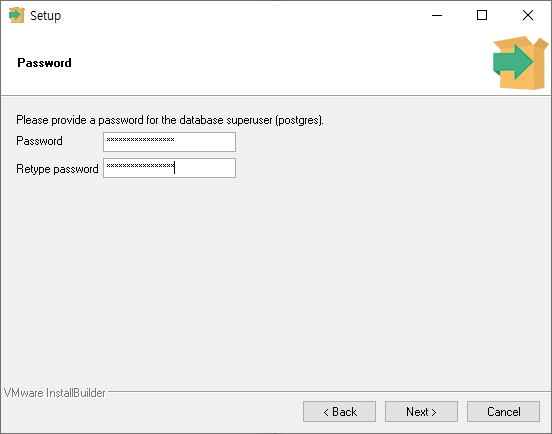
서버의 기본 포트 번호를 설정합니다. 기본 값은 5432입니다.
포트 설정 후 'Next' 버튼을 클릭하면 Locale 설정 화면을 볼 수 있습니다.
Locale을 [Default locale]로 선택하면 OS에 설정된 locale 정보를 따라가게 됩니다.
'Next' 버튼을 클릭하면
지금까지 설정한 설치 정보를 최종적으로 확인할 수 있습니다.
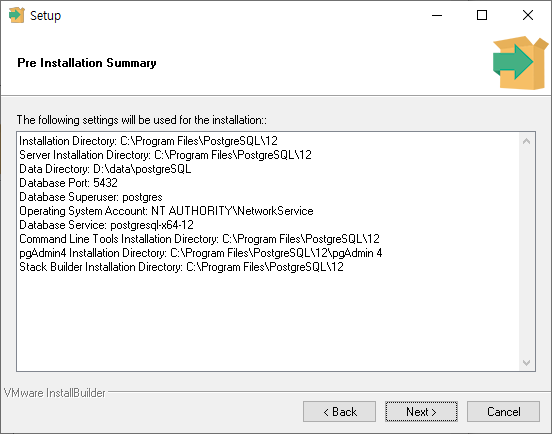
설치 정보가 정상인지 확인했다면 'Next' 버튼을 클릭하여 설치를 시작합니다.
설치가 시작되며, Progress bar를 통해 진행률을 확인하실 수 있습니다.
설치가 정상적으로 완료되면 아래와 같은 다이얼로그를 확인하실 수 있습니다.

설치 마법사가 종료된 후 Stack Builder를 실행하여 추가적인 드라이버나 툴을 설치하려면 위 화면 가운데의 체크 박스를 선택합니다.
Stack Builder에 대해서는 별도의 포스트에서 언급할 계획이니, 여기서는 체크 박스를 해제하도록 하겠습니다.
'Finish' 버튼을 클릭하면 PostgreSQL 설치가 마무리됩니다.
3. postgreSQL 실행
PostgreSQL 설치 후 윈도우 시작 메뉴를 확인하면 아래와 같이 시작 메뉴가 생성된 것을 확인하실 수 있습니다.
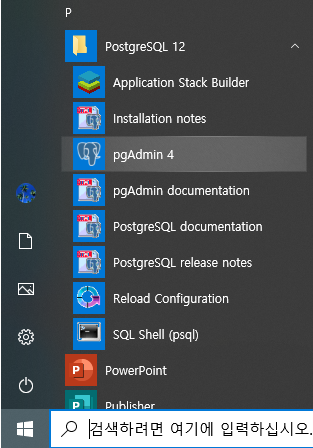
위 메뉴 중 pgAdmin을 이용해 데이터베이스에 접속해보도록 하겠습니다.
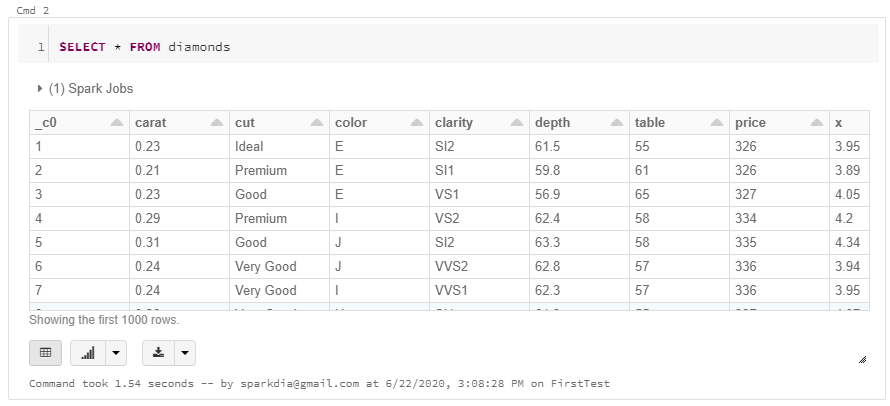
pgAdmin을 실행하면 아래와 같이 웹브라우저에서 pgAdmin 웹페이지(기본 URL : http://127.0.0.1:59594/browser)를 확인하실 수 있습니다.
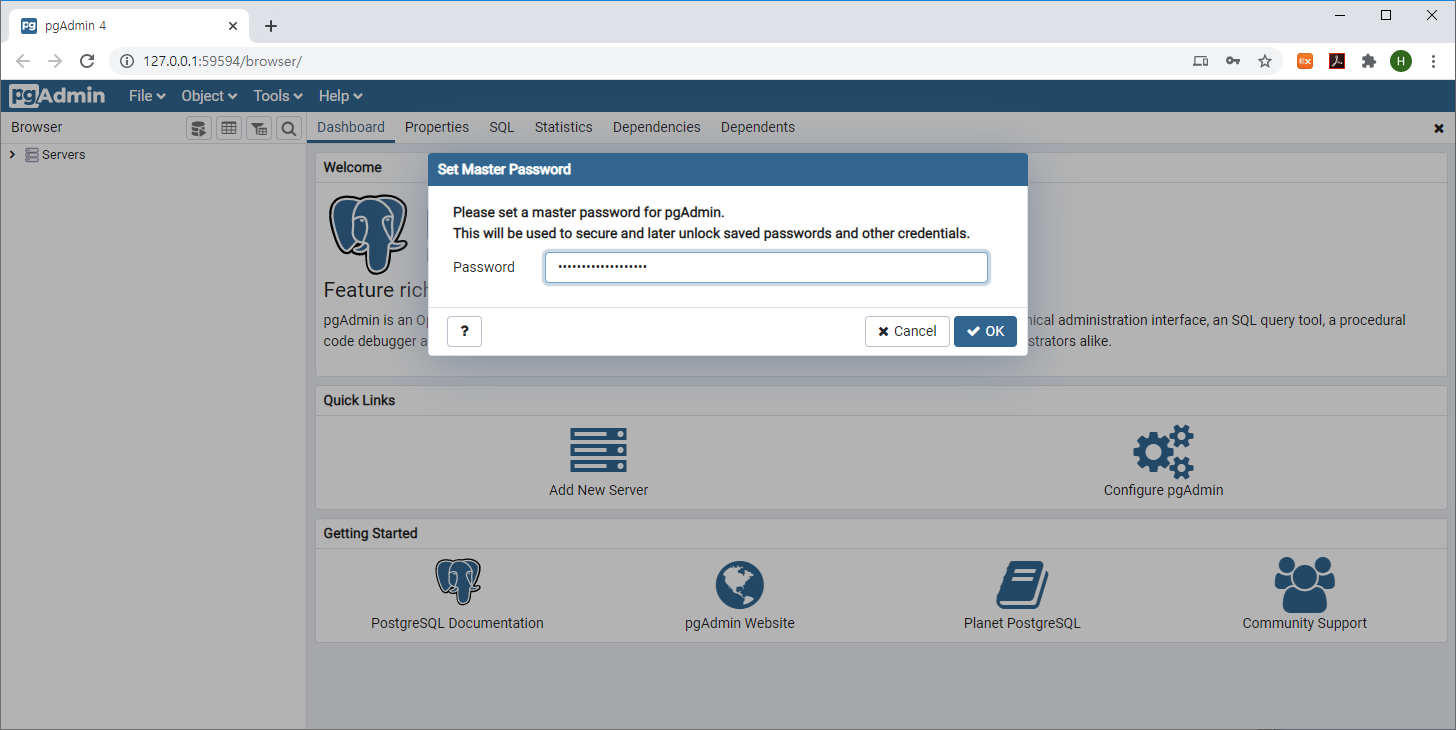
설치시 설정한 super 사용자 계정 비밀번호를 입력 후 'OK' 버튼을 클릭합니다.
비밀번호를 입력하여 로그인을 하면
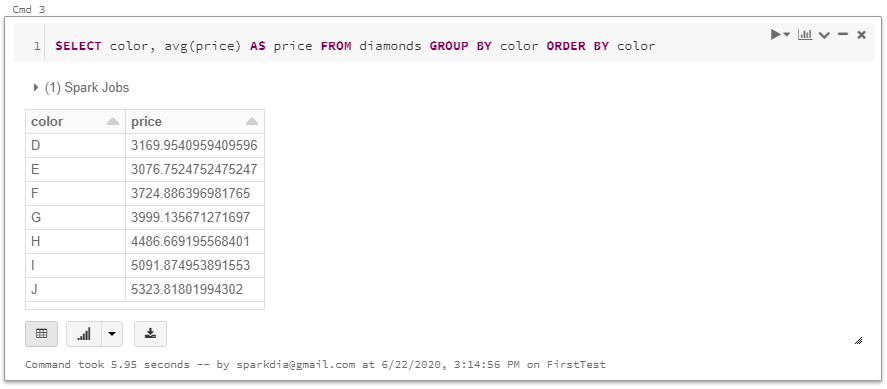
아래와 같이 접속된 서버 목록 및 서버 정보(데이터베이스, Role, 테이블스페이스 등)와 서버의 상태를 확인할 수 있는 대시보드를 보실 수 있습니다.
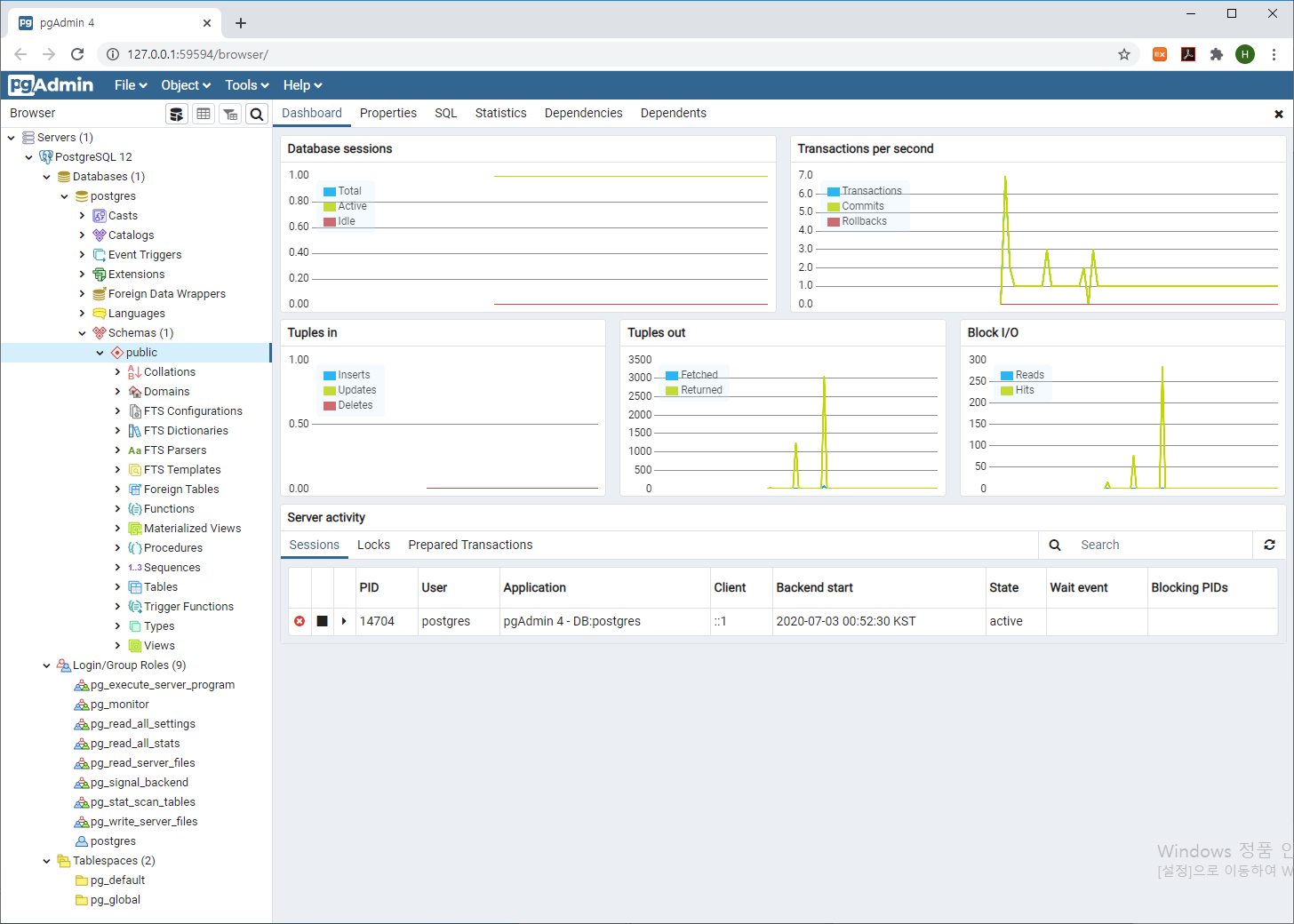
4. PostgreSQL 시작 및 중지
윈도우윈도 환경에서의 PostgreSQL은 윈도우 서비스를 통해 서비스 시작/중지 작업을 진행할 수 있습니다.
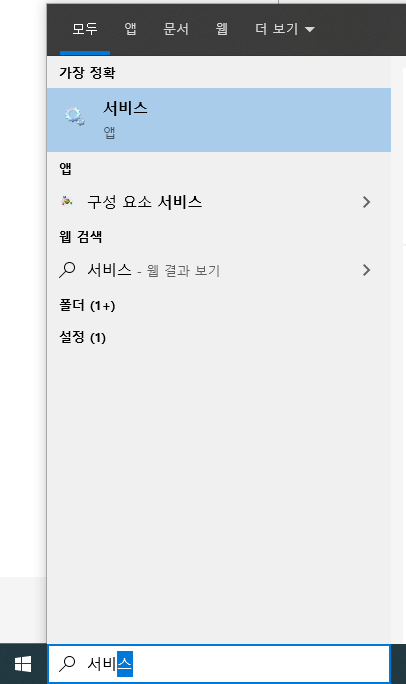
윈도우 시작 메뉴에서 서비스를 검색하거나 'services.msc'를 실행합니다.
서비스 프로그램이 실행되면 오른쪽 서비스 목록 중에 'postgresql-x64-12'를 확인하실 수 있습니다.
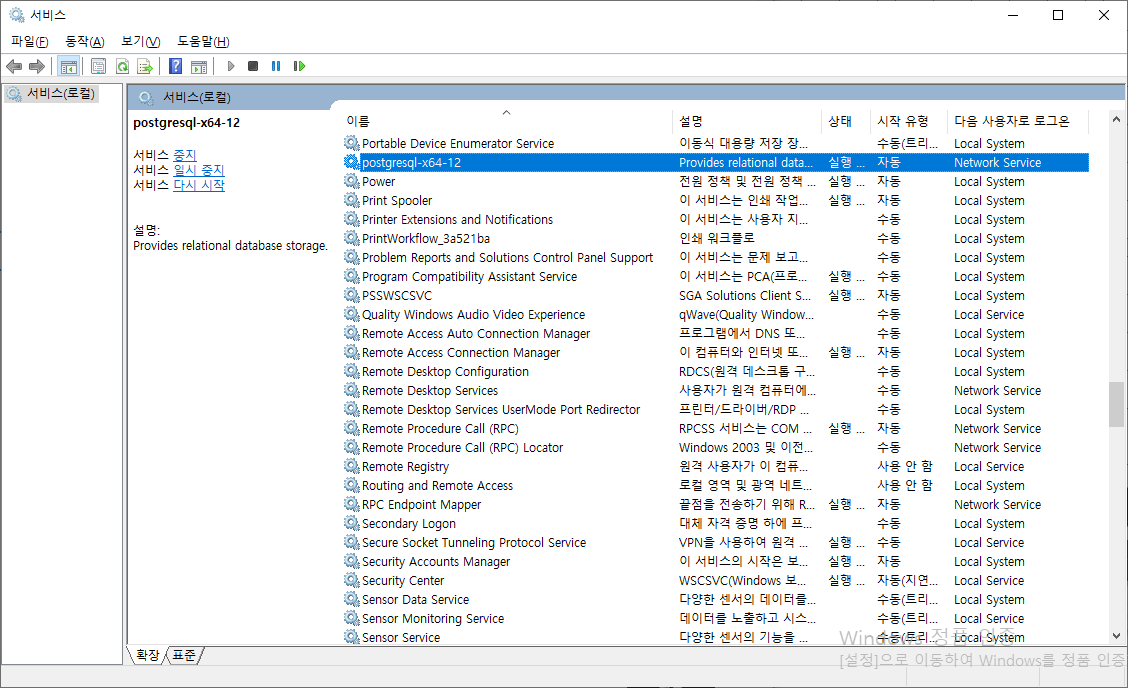
postgresql-x64-12를 선택 후 오른쪽 버튼을 클릭 후 나타난 팝업 메뉴 중 '속성'을 클릭하여 서비스 정보를 확인합니다.
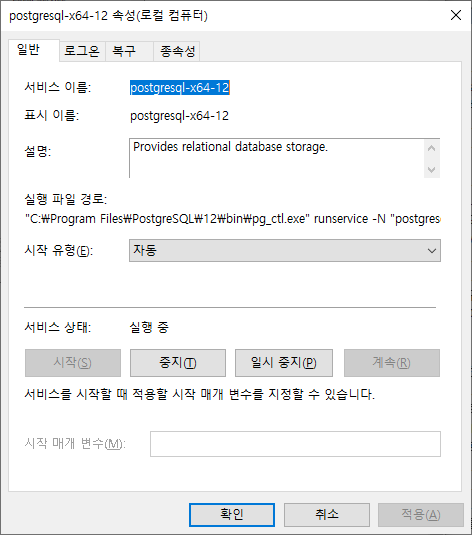
postgreSQL를 설치하면 기본적으로 서비스에 등록되며, 윈도우 가동 시 자동으로 서비스가 시작되게 설정되어 있습니다.
postgreSQL을 종료하기 위해서는 위 속성 다이얼로그 내 '중지' 버튼을 클릭하면 됩니다.
postgreSQL 서비스가 중지되면 아래 '서비스 상태'가 '중지됨'으로 변경됩니다.
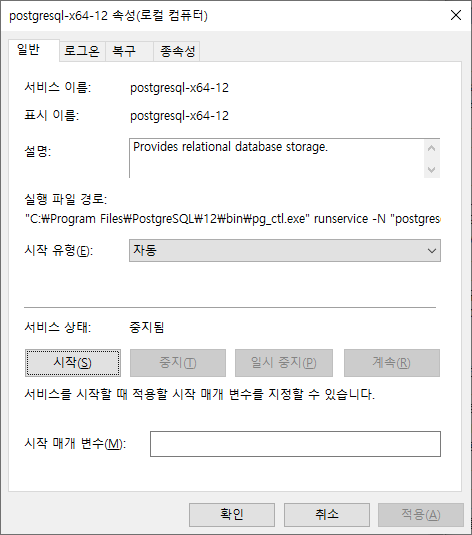
다시 서비스를 시작하기 위해서는 속성 다이얼로그 내 '시작' 버튼을 클릭하면 됩니다.
postgreSQL 서비스가 정상적으로 가동되었다면 아래 다이얼로그처럼 '서비스 상태'가 '실행 중'으로 변경된 것을 확인하실 수 있습니다.
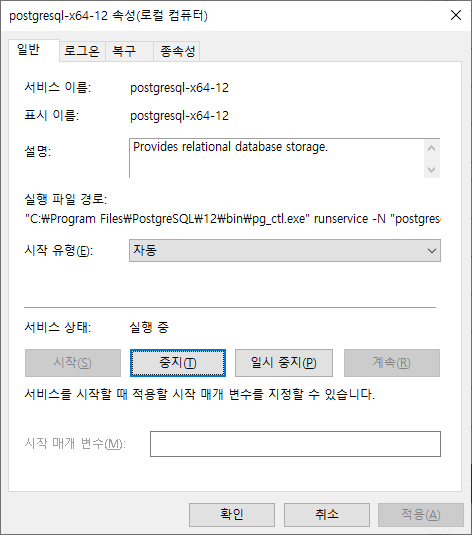
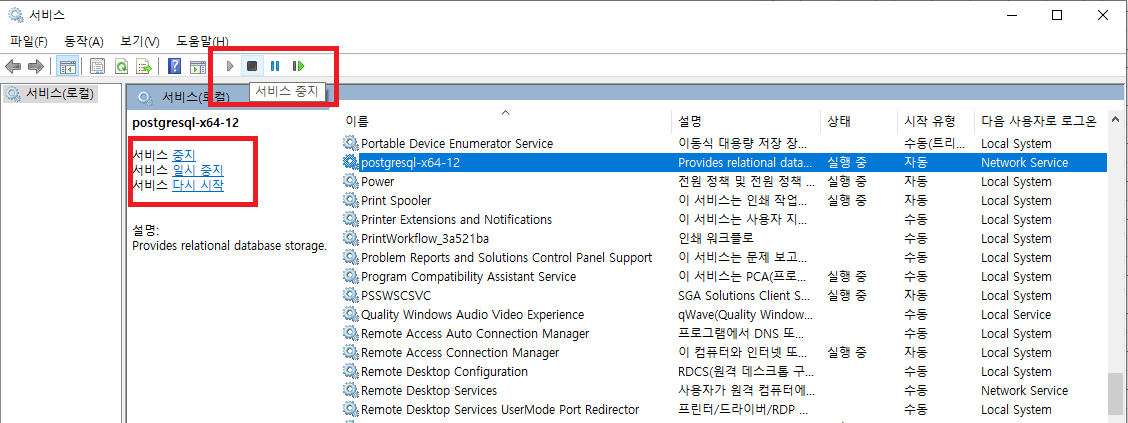
postgreSQL의 시작과 중지 작업은 속성 다이얼로그 외에도
아래 화면에 표시된 툴바나 목록 왼쪽의 메뉴를 통해서도 작업이 가능합니다.
'Database > PostgreSQL' 카테고리의 다른 글
| PostgreSQL 기본 테스트 - psql (0) | 2020.07.03 |
|---|