데이터 브릭스(Databricks)는 아파치 스파크 실행환경을 제공해주는 클라우드 기반의 플랫폼입니다.
Notebook 형태로 스파크 소스를 테스트할 수 있는 웹 UI환경을 제공해주므로, 설치 작업 없이도 스파크를 직접 테스트해 볼 수 있습니다.
데이터브릭스는 두 개의 플랫폼 DATABRICKS PLAFORM과 COMMUNITY EDITION이 존재합니다.
BUSINESS용인 DATABRICKS PLAFORM은 제약 없이 모든 기능을 사용할 수 있으며. 무료로 Trial 버전을 14일간 사용할 수 있습니다.
COMMUNITY EDITION은 스파크 학습자를 위한 무료 버전으로 기능이 제한적입니다.
데이터브릭스를 사용하기 위해서는 아래 URL에 접속하여 사용자 등록을 해야 합니다.
* URL : https://databricks.com/try-databricks
Try Databricks
Discover why businesses are turning to Databricks to accelerate innovation. Try Databricks’ Full Platform Trial risk-free for 14 days!
databricks.com
위 URL에 접속하면 아래와 같이 사용자 기본 정보를 입력하는 화면이 표시됩니다.

개인 정보를 입력 후 'SIGN UP' 버튼을 클릭하면 데이터브릭스 버전을 선택하는 화면이 표시됩니다.
이 포스트에서는 Commuity edtion을 선택하여 테스트를 진행해보도록 하겠습니다.

Commuity edtion의 'GET STARTED' 버튼을 클릭하면 아래와 같이 이메일을 확인하라는 메세지가 출력됩니다.

이메일 본문 중에서 'Get started by visiting' 오른쪽의 링크를 클릭하여 이메일을 인증합니다.

위 링크를 클릭하면 아래와 같이 계정 비밀번호을 설정하는 화면으로 이동합니다.

비밀번호 변경 작업이 완료되면 아래와 같이 데이터브릭스 초기 화면을 볼 수 있습니다.
화면 중앙에 'Explore the Quickstart Tutorial'을 클릭하면 기본 사용 방법이 정리된 Notebook을 확인하실 수 있습니다.
이 포스트에서도 위 튜토리얼을 따라서 테스트를 진행해보도록 하겠습니다.

데이터브릭스를 사용하기 위해서는 제일 먼저 클러스터를 생성해야 합니다.
위 화면에서 'New Cluster'를 클릭하여 클러스터 생성 작업을 진행합니다.
또는 아래와 같이 왼쪽 메뉴에서 'Clusters'를 클릭한 후 나타나는 Clusters 페이지 상단의 'Create Cluster' 버튼을 클릭하여 클러스터를 생성할 수도 있습니다.

클러스터 생성화면에서 생성할 클러스터의 이름을 입력하고, Runtime Version을 선택합니다.
Runtime Version은 테스트하고자 하는 Scala나 Spark의 버전을 기준으로 선택하면 됩니다.
여기서는 튜토리얼에서 제시된 6.3 (Scala 2.11, Spark 2.4.4) 버전을 선택하도록 하겠습니다.

입력이 완료되면 'Create Cluster' 버튼을 클릭하여 클러스터를 생성합니다.
Clusters 페이지에서 생성된 클러스터를 확인할 수 있습니다.

이어서 Notebook을 생성하도록 하겠습니다.

위 초기화면 중앙에 위치한 'New Notebook' 메뉴를 클릭하여 신규 노트북을 생성할 수 있습니다.
또는 아래와 같이 메뉴 'Workspace'에서 계정명 옆의 '∨' 아이콘을 클릭하면 아래와 같이 Notebook을 생성하는 메뉴를 확인하실 수 있습니다. 해당 메뉴를 통해서도 노트북 생성이 가능합니다.

노트북 생성 메뉴를 실행하면 아래와 같이 노트북 생성 화면이 표시됩니다.

노트북 이름을 입력하고 'Defalut Language'는 우선 SQL을 선택하도록 하겠습니다.
'Cluster'는 방금 전에 생성한 클러스터를 선택하면 됩니다.
'Create' 버튼을 클릭하면 아래와 같이 생성된 노트북 페이지가 표시됩니다.

데이터브릭스에서 제공해주는 diamonds.csv 파일을 소스 데이터로 읽어들이는 diamonds 테이블을 생성하도록 하겠습니다.
DROP TABLE IF EXISTS diamonds;
CREATE TABLE diamonds
USING csv
OPTIONS (path "/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", header "true")
노트북 셀(cells) 또는 커맨드(commands)에 위 SQL을 입력한 후 실행합니다.
셀에서 shift+Enter를 입력하거나 셀 오른쪽 상단의 '▶' 아이콘을 클릭하면 해당 셀 내 SQL이 실행됩니다.

SQL을 실행하면 위와 같이 셀 하단에 Spark Jobs 목록과 실행 결과가 표시됩니다.
위에서 생성한 테이블은 'Data' 메뉴에서도 확인 가능합니다.

방금 생성한 diamonds 테이블의 데이터를 조회해보도록 하겠습니다.
SELECT * from diamonds
GROUP BY 구문을 사용해 색상(color)별 평균 가격(price)을 계산할 수도 있습니다.
SELECT color, avg(price) AS price FROM diamonds GROUP BY color ORDER BY color
Select문을 실행하여 출력된 데이터는 테이블 형태나 다양한 형태의 그래프로 확인할 수 있습니다.
결과 데이터 셋 화면 아래에 Bar 그래프 아이콘을 클릭하면 다양한 형태의 그래프 옵션을 볼 수 있으며, 출력하고자 하는 형태의 그래프를 선택하여 쉽게 그래프를 출력할 수 있습니다.

아래는 diamonds 테이블 데이터의 색상별 평균 가격을 Bar 그래프로 출력한 결과입니다.

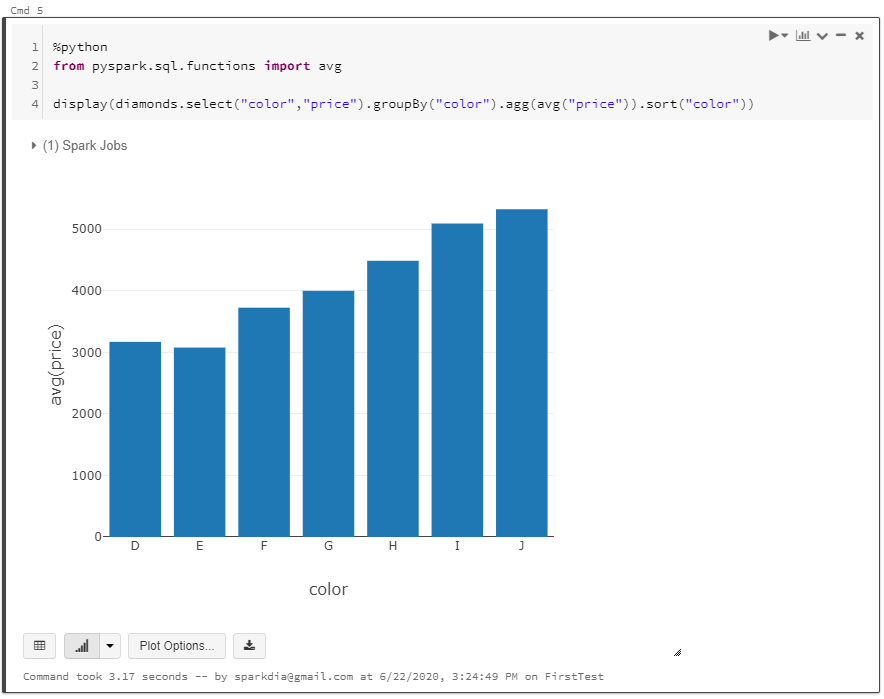
현재 테스트 중인 노트북의 기본 언어를 SQL로 선택했지만 '%python' 명령어를 이용해 파이썬 명령어도 해당 노트북에서 실행할 수 있습니다.
위에서 SQL로 테스트한 작업을 파이썬 명령어를 이용해서 다시 테스트해보도록 하겠습니다.
diamonds.csv 파일을 읽어 diamonds 데이터 프레임을 생성합니다.
%python
diamonds = spark.read.csv("/databricks-datasets/Rdatasets/data-001/csv/ggplot2/diamonds.csv", header="true", inferSchema="true")
diamonds 데이터 프레임에서 색상(color)별 평균 가격(price)를 추출합니다.
%python
from pyspark.sql.functions import avg
display(diamonds.select("color","price").groupBy("color").agg(avg("price")).sort("color"))
위 실행 결과도 아래와 같이 그래프로 확인해보겠습니다.
'BigData > Spark' 카테고리의 다른 글
| 스파크(Spark) 3.0.0 설치 on Windows 10 (0) | 2020.06.28 |
|---|---|
| Spark 2.1.3 설치 (CentOS 8) (0) | 2020.06.14 |