2010년에 처음 선 보인 Spark가 10주년이 되는 올해 6월 18일에 3.x 대 첫 버전인 3.0.0 릴리즈를 공개했습니다.
Spark 3.0에서 기능 개선이 가장 많았던(top active component) 것은 Spark SQL인데요. TPC-DS 30TB 벤치마크 테스트에서 Spark 2.4 비해 2배 정도 빠른 성능을 보여줬다고 합니다.
그 외 Spark 3.0의 주요 New feature는 아래와 같습니다.
- adaptive query execution
- dynamic partition pruning
- ANSI SQL compliance
- significant improvements in pandas APIs
- new UI for structured streaming
- up to 40x speedups for calling R user-defined functions
- accelerator-aware scheduler
이제 본격적으로 Spark 3.0.0을 설치해보도록 하겠습니다.
1. 자바 설치
스파크는 스칼라로 구현되어 있으며, 자바 가상 머신(JVM) 기반에서 동작합니다.
따라서, 스파크를 설치하기 위해서는 사전에 자바가 설치되어야 합니다.
스파크 3.0.0은 자바 11버전을 지원하므로, JDK 11 버전을 다운로드 받아 설치합니다.
* URL : https://spark.apache.org/releases/spark-release-3-0-0.html
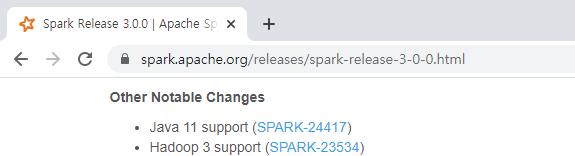
Java SE 11 버전 설치는 아래 포스트를 참고 바랍니다.
https://sparkdia.tistory.com/64
Java SE 11 설치 on Windows 10
윈도우 10 환경에서 Java se 10 설치 작업을 진행해보겠습니다. 이 포스트를 작성하는 시점에 릴리즈된 DK 최신 버전은 14입니다. 하지만 제가 설치하고자 하는 프로그램과 호환이되는 버전이 필��
sparkdia.tistory.com
2. 파이썬(Python) 설치
스파크 3.0.0에서 파이썬 2 버전대는 더 이상 지원하지 않는다고 합니다.
아래 파이썬 홈페이지 접속하여 최신 버전인 3.8.3을 다운로드받아 설치합니다.
https://www.python.org/downloads/
Download Python
The official home of the Python Programming Language
www.python.org

3. 스파크 다운로드 및 압축해제
아래 URL에 접속하여 스파크 다운로드 페이지로 이동합니다.
* URL : https://spark.apache.org/downloads.html
Downloads | Apache Spark
Download Apache Spark™ Choose a Spark release: Choose a package type: Download Spark: Verify this release using the and project release KEYS. Note that, Spark 2.x is pre-built with Scala 2.11 except version 2.4.2, which is pre-built with Scala 2.12. Spar
spark.apache.org
스파크 릴리즈를 3.0.0으로 선택하고, 하둡 3.2가 포함된 패키지를 선택합니다.
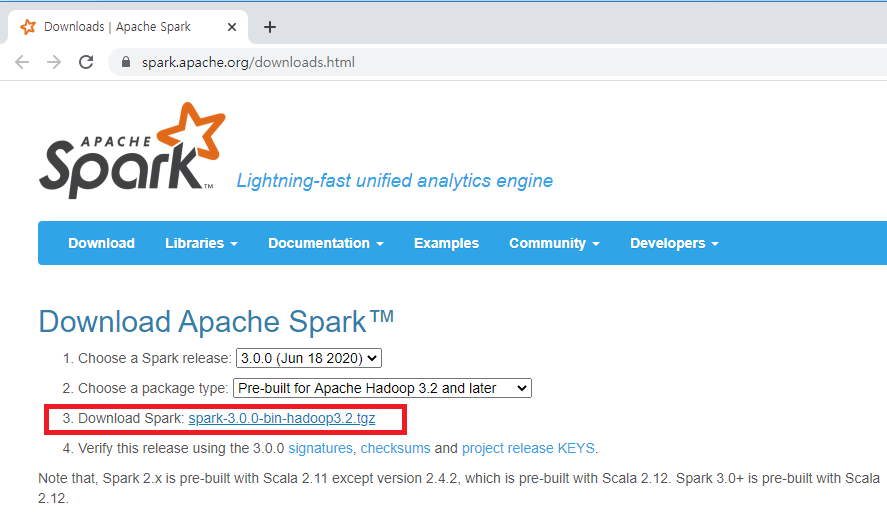
Download Spark 옆의 링크를 클릭하면 다운로드가 가능한 미러 사이트 목록이 표시되는 아래 페이지로 이동합니다.
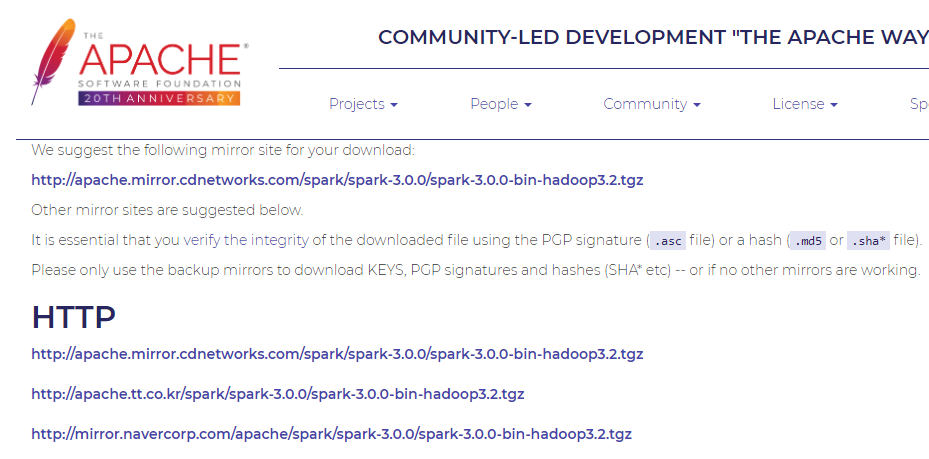
위 미러 사이트 중 한 곳을 선택하여 설치 파일을 다운로드 받습니다.
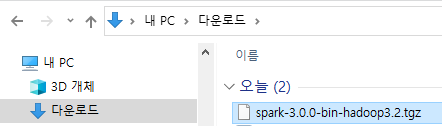
4. 스파크 설치
다운로드 받은 파일을 설치하고자 하는 디렉토리(예: C:\Spark\)에 옮긴 후 압축을 해제합니다.
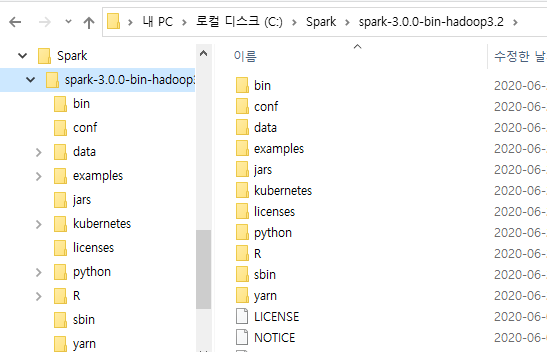
5. Winutils 설치
아래 URL에 접속하여 Spark 다운로드 시 선택한 하둡 버전에 맞는 winutils.exe 파일을 다운로드 받아야 합니다.
* URL : https://github.com/cdarlint/winutils
이 포스트에서는 하둡 3.2 버전을 선택하였으므로 하단 URL에 접속하여 winutils.exe 파일을 다운로드 합니다.
* URL : https://github.com/cdarlint/winutils/tree/master/hadoop-3.2.1/bin
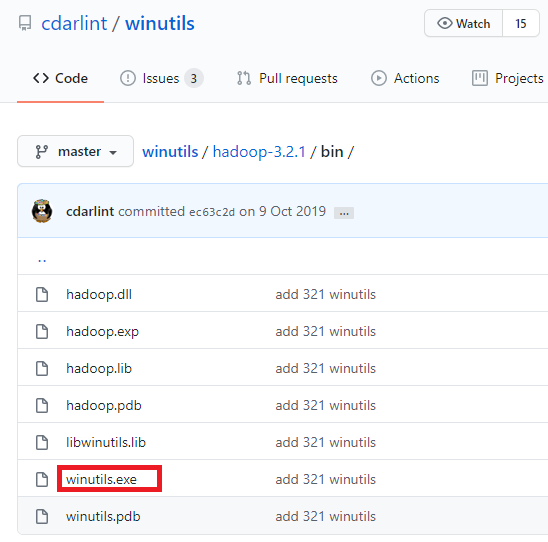
위 페이지의 winutils.exe 링크에서 오른쪽 마우스를 클릭하여 팝업 메뉴를 띄웁니다. 팝업 메뉴 중 '다른 이름으로 링크 저장'을 클릭하여 winutils.exe 파일을 다운로드 합니다.
C:\에 Hadoop\bin 디렉토리를 생성합니다. 생성된 bin 디렉토리에 다운로드 받은 winutils.exe 파일을 이동시킵니다.
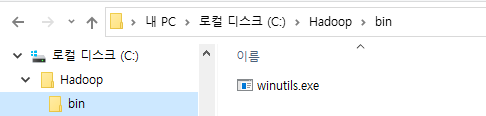
6. 환경설정
탐색기에서 [내 PC]를 선택 후 마우스 오른쪽 버튼을 클릭하여 팝업 메뉴를 띄웁니다. 팝업 메뉴 중 하단의 '속성'을 클릭합니다.
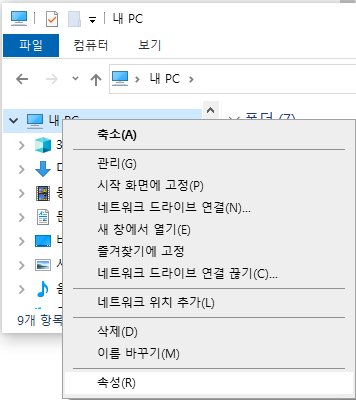
왼쪽 메뉴 하단의 '고급 시스템 설정'을 클릭합니다.
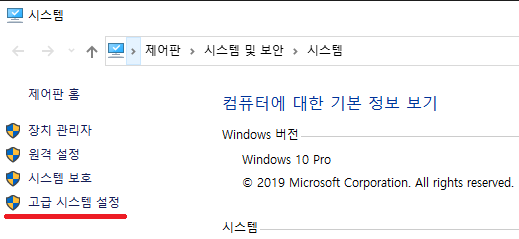
시스템 속성 다이얼로그에서 '고급' 탭을 선택 후 하단의 '환경 변수' 버튼을 클릭합니다.
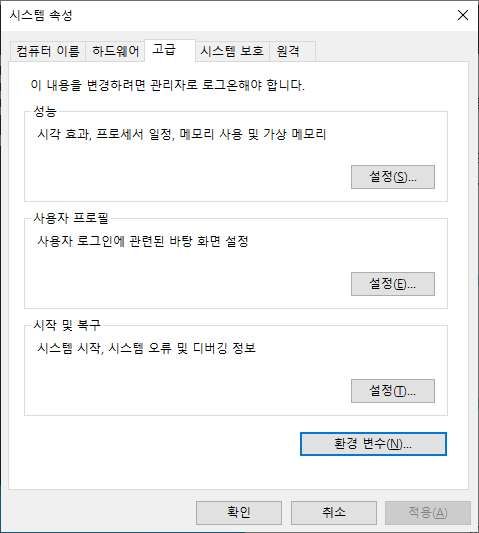
환경 변수 다이얼로그의 '시스템 변수'에서 '새로 만들기'를 클릭합니다.
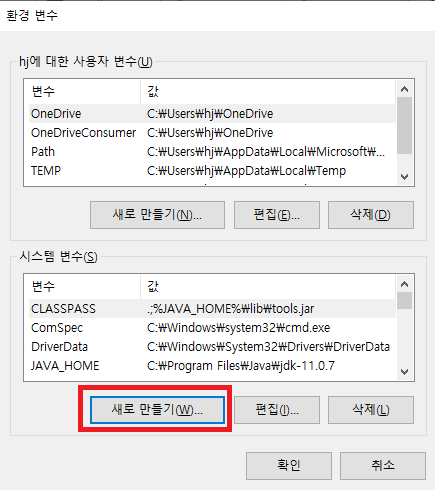
변수 이름은 'SPARK_HOME', 변수 값은 스파크 설치 디렉토리 명(예: C:\Spark\spark-3.0.0-bin-hadoop3.2)을 입력합니다.
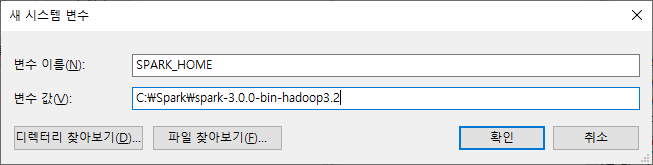
다시 한번 '새로 만들기' 버튼을 클릭 후 변수 이름은 'HADOOP_HOME', 변수 값은 'C:\Hadoop'을 입력합니다.
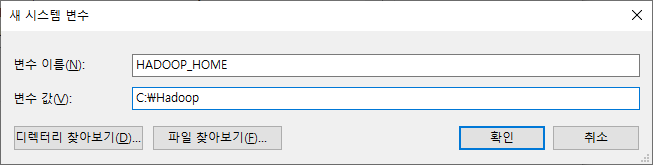
시스템 변수 중 'Path'를 선택 후 '편집' 버튼을 눌러 아래와 같이 '%SPARK_HOME%\bin'과 '%HADOOP_HOME%\bin 경로를 추가해줍니다.
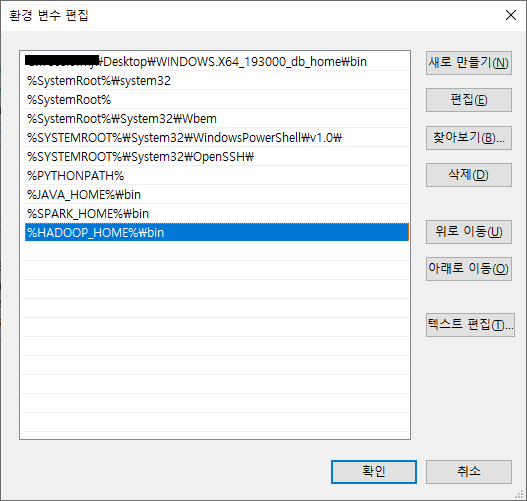
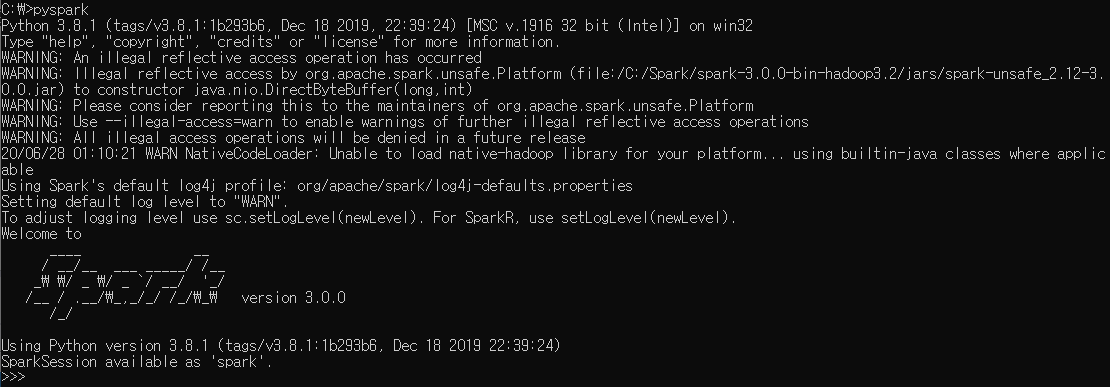
7. 스파크 실행
명령 프롬프트를 실행하여 커맨드에서 pyspark를 입력하면 아래와 같이 pyspark가 실행되는 것을 확인하실 수 있습니다.
테스트로 prod_list.csv 파일을 읽어 prod라는 데이터프레임을 생성한 후, COLOR별 건수를 출력하는 예제를 실행해보았습니다.
prod = spark.read.csv("C:\\Spark\\sample\\prod_list.csv", header="true", inferSchema="true")
prod.groupBy("COLOR").count().show()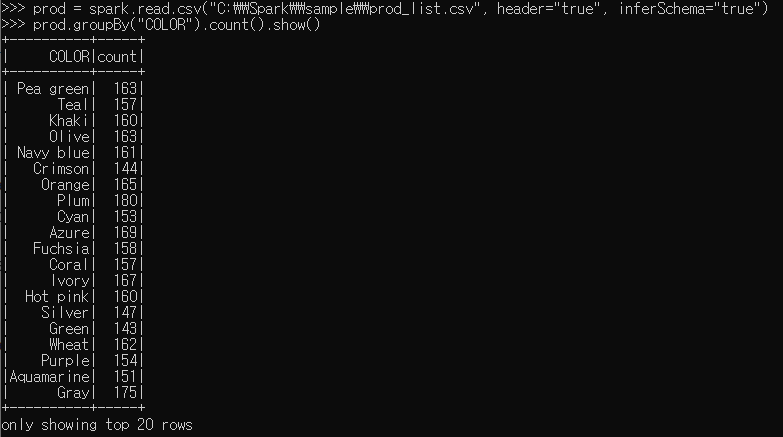
8. 스파크 Web UI
아래 URL을 통해서 스파크 웹 UI에 접속 가능합니다.
* URL : http://localhost:4040/
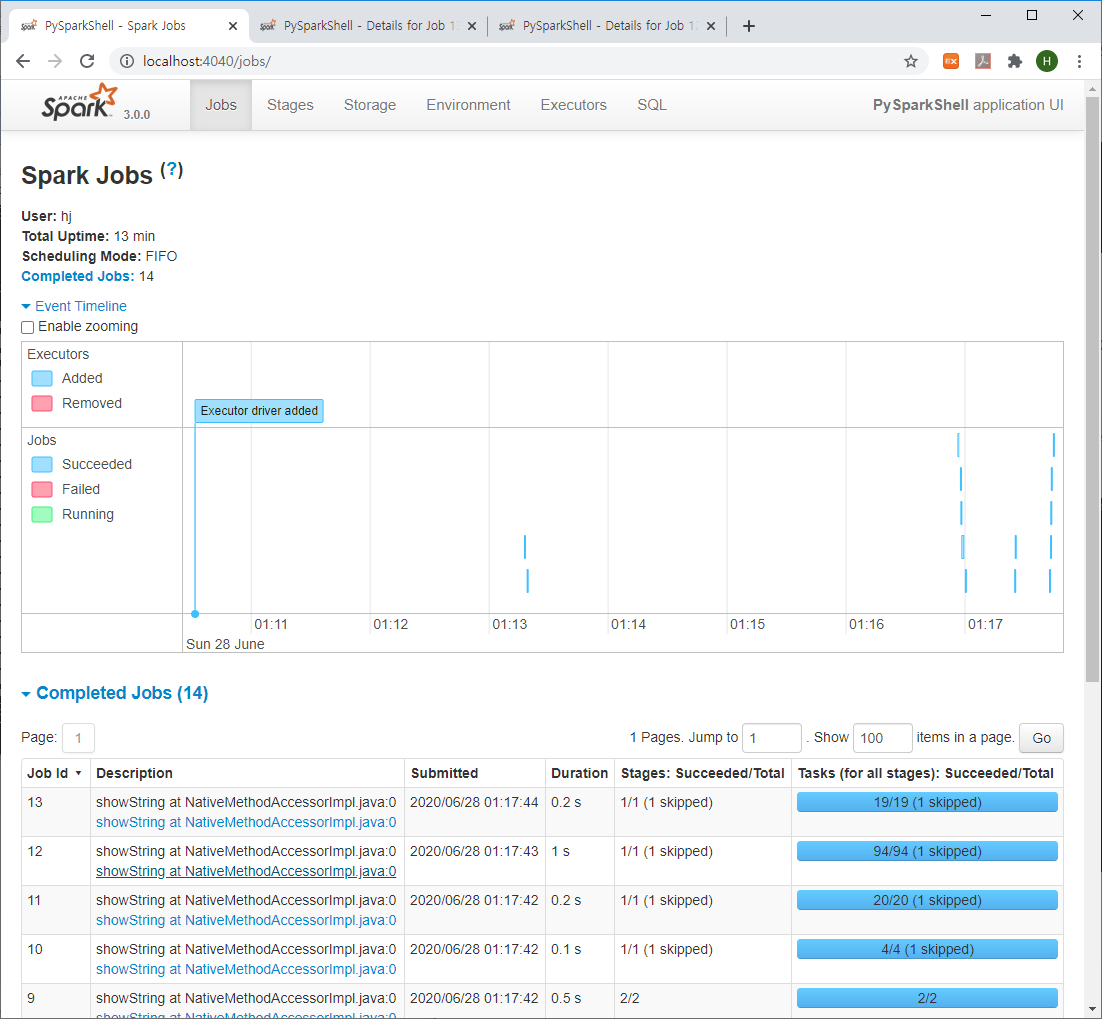
스파크 내에서 실행 중인 잡 목록을 모니터링 할 수 있으며, 아래와 같이 Stage별 DAG도 확인이 가능합니다.
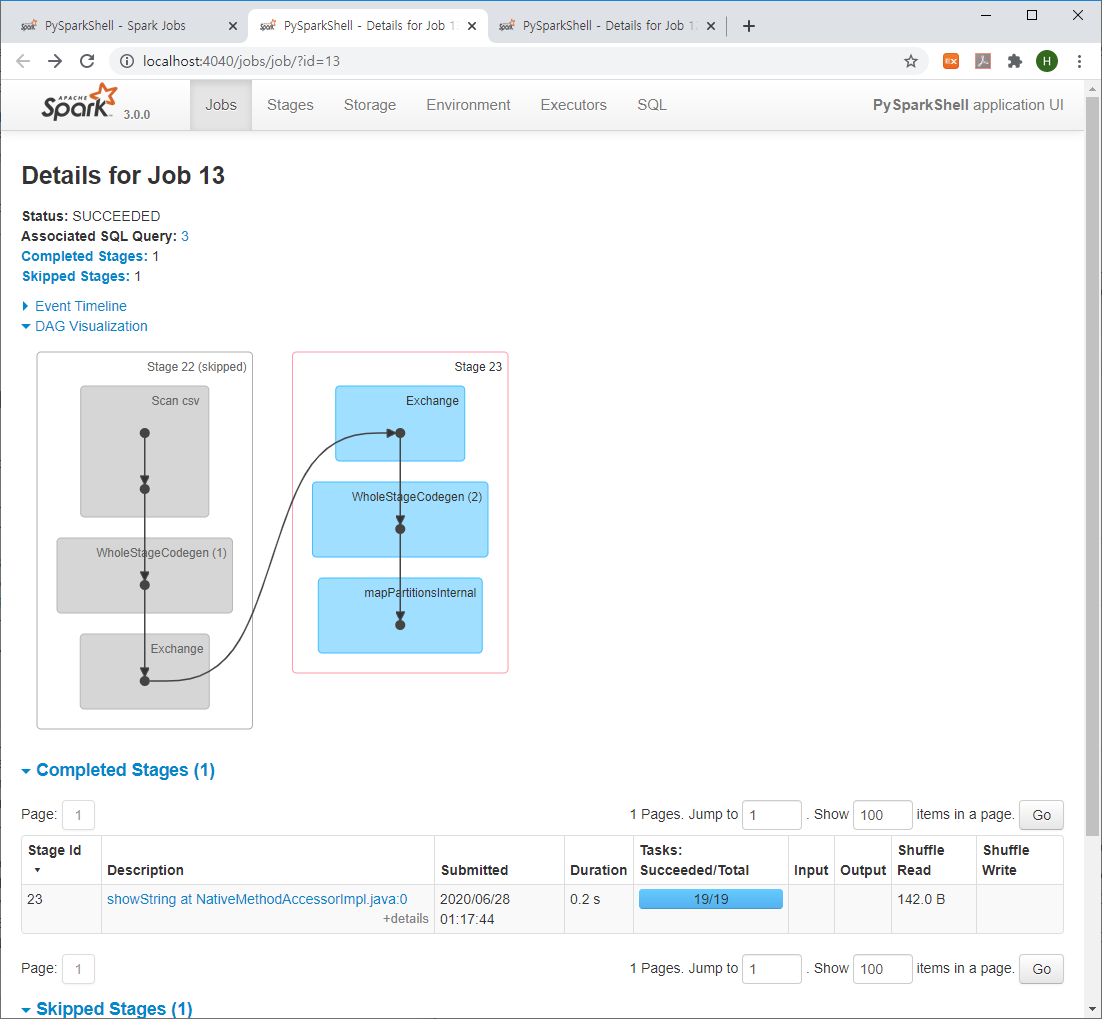
[Ref.] https://phoenixnap.com/kb/install-spark-on-windows-10
'BigData > Spark' 카테고리의 다른 글
| 스파크(Spark) 실행하기 on Databricks (2) | 2020.06.22 |
|---|---|
| Spark 2.1.3 설치 (CentOS 8) (0) | 2020.06.14 |