맵리듀스(Map-Reduce) 데이터 흐름
하둡 맵리듀스는 클러스터 환경에서 대량의 데이터를 병렬로 처리하는 응용 프로그램을 쉽게 작성할 수 있는 소프트웨어 프레임워크입니다. 맵리듀스 작업은 일반적으로 입력 데이터를 독립적
sparkdia.tistory.com
이전 포스팅에서 맵리듀스의 데이터 흐름을 간략하게 살펴보았습니다.
일반적으로 Mapper와 Reducer 인터페이스의 map과 reduce 메소드를 구현하는 것만으로도 간단하게 맵리듀스 프레임워크를 사용할 수 있습니다.
만약, 입/출력 대상으로 텍스트 파일 외 다른 형식의 파일이나 데이터베이스를 사용하는 경우나 맵리듀스 내부의 상세 작업을 컨트롤하기 위해서는 추가적인 개발 작업이 필요합니다.
이를 위해 맵리듀스의 작동 방법을 좀 더 상세하게 살펴보도록 하겠습니다.
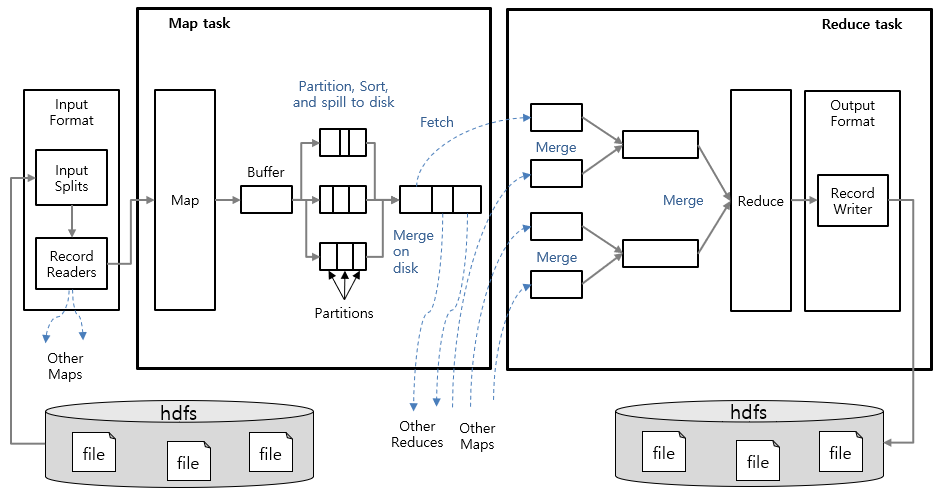
맵리듀스 Job은 클라이언트가 수행하는 작업의 기본 단위로, 맵 태스크(Map task)와 리듀스 태스크(Reduce task)로 나눠서 실행합니다.
1. Map task 단계
Map task 단계에서는 입력 데이터를 읽어 <key, value> 구조의 입력 레코드를 구성한 뒤 중간 단계의 레코드로 변환하는 작업을 합니다.
맵리듀스 프레임워크의 입력으로 다양한 형식의 입력 데이터가 사용 될 수 있습니다. 물론, 하둡에서 제공되는 기본 파일 형식외에는 입력 파일의 형식이 무엇이고 어떻게 레코드 형태로 변환할 수 있는지 정의하는 작업은 필요합니다. 이러한 작업은 InputFormat과 RecordReader라는 인터페이스를 확장 구현하여 정의 가능합니다.
InputFormat
InputFormat은 맵리듀스 Job의 입력 명세서라고 표현할 수 있습니다.
맵리듀스 프레임워크에서는 Job의 InputFormat을 이용해 아래와 같은 작업을 수행합니다.
1) 작업의 입력 명세서를 검증
2) 입력 파일을 분할하여 InputSplit을 생성한 뒤, 각 개별 Mapper에 할당
3) Mapper가 처리할 입력 레코드를 InputSplit에서 어떻게 추출해야 할 지 명시하는 RecordReader를 구현
InputFormat을 구현한 기본 클래스는 FileInputFormat이며, 이를 확장한 다수의 하위 클래스가 존재합니다. 대표적으로 기본 InputFormat인 TextInputFormat 클래스도 FileInputFormat의 하위 클래스입니다. FileInputFormat의 하위 클래스의 기본 동작은 입력 파일의 총 크기(Byte)을 기준으로 입력을 논리적 InputSplit 인스턴스로 분할하는 것입니다.
InputSplit
InputSplit은 Job의 입력을 고정 크기로 분리한 데이터 조각입니다. 입력 데이터를 다수의 Mapper가 병렬로 분산 처리할 수 있도록 다수의 논리적인 InputSplit으로 분리한 것입니다.
하나의 InputSplit마다 맵 태스크를 생성하게 되며, InputSplit의 각 레코드는 RecordReader에 의해 <key, value> 형태인 입력 레코드로 변환되어 map 함수로 전달됩니다.
RecordReader
RecordReader는 입력 데이터가 크기 기준(byte-oriented view)으로 분리된 InputSplit을 Mapper에서 <key, value> 쌍 형태로 처리할 수 있도록 레코드 기반의 형태(record-oriented view)로 변환하는 작업을 수행합니다.
LineRecordReader는 TextInputFormat이 제공하는 기본 레코드 입력기입니다. LineRecordReader는 정의된 레코드 delimiter(기본 값은 개행 문자)에 의해 입력 데이터를 분리합니다. 이 때, 분리된 각 문자열이 레코드의 value가 되며, key는 파일에서 해당 문자열의 위치(Byte offset)입니다.
Map
맵에서는 입력 데이터를 읽어 map 함수에서 사용자가 정의한 연산을 수행합니다.
맵 함수의 처리 결과는 우선 메모리 버퍼에 저장되며 버퍼의 내용이 한계치에 도달하면 일괄로 디스크에 저장(Spill)됩니다. 이 때, 맵의 출력 데이터는 키 값에 의해 정렬되고 리듀서 수에 맞게 파티션별로 나눠서 저장됩니다. 파티션 별로 출력 데이터를 나눠서 저장하는 이유는 리듀서별로 전송할 출력 데이터를 미리 구분하기 위해서입니다.
만약, 컴바이너 함수가 정의되어 있다면 맵의 출력 값이 컴바이너 함수의 입력 값이 되고, 컴바이너 함수의 결과 데이터에 대해 정렬과 파티셔닝 작업이 발생하게 됩니다. 컴바이너 함수를 사용하는 이유는 맵 결과 데이터의 크기를 감소시켜 리듀서로 전송할 데이터 양(네트워크 부하)을 줄이기 위함입니다.
2. Reduce task 단계
Reduce
리듀스 태스크는 각 맵 태스크가 완료되는 즉시 맵의 출력 데이터를 리듀스가 실행되는 노드에 복사하기 시작합니다(Shuffle).
맵의 출력 데이터가 복사될 때 리듀서는 다수의 맵 출력 데이터를 정렬 순서를 유지하면서 병합합니다.
리듀스에서는 병합된 데이터를 읽어 reduce 함수에서 사용자가 정의한 연산을 수행합니다.
OutputFormat
OutputFormat은 맵리듀스 Job의 출력 명세서라고 표현할 수 있습니다.
맵리듀스 프레임워크에서는 Job의 OutputFormat을 이용해 아래와 같은 작업을 수행합니다.
1) 작업의 출력 명세서를 검증 (예: 출력 디렉토리 존재 여부)
2) 작업의 출력 파일을 작성하는 데 사용되는 RecordWriter 구현
RecordWriter
RecordWriter는 출력 <key, value> 쌍을 출력 파일에 씁니다.
RecordWriter을 구현한 기본 클래스는 LineRecordWriter입니다. LineRecordWriter은 key와 value를 tab 문자로 구분하며, 각 레코드는 개행 문자로 구분하여 데이터를 저장합니다.
이상으로 맵리듀스의 작동 방법에 대해 알아봤습니다.
맵리듀스의 작동 원리를 이해하게 되면, 맵리듀스 구현이 용이해지고 디버깅 작업이 좀 더 수월해질 수 있을것입니다. 또한, Hive 등 하둡 에코 시스템에서의 데이터를 저장하고 관리하는 방법에 대한 이해도도 높아질 수 있으실 것입니다.
만약, 위 내용에 대해서 오류를 발견하시거나 궁금한 사항이 있으시면 적극적인 의견 부탁드립니다.
[Ref.] Hadoop, The Definitive Guide
https://hadoop.apache.org/docs/r1.2.1/mapred_tutorial.html
'BigData > Hadoop' 카테고리의 다른 글
| 맵리듀스(Map-Reduce) 데이터 흐름 (0) | 2020.05.23 |
|---|---|
| Hadoop YARN (0) | 2020.05.11 |
| HDFS 아키텍처 (0) | 2020.05.11 |
| 하둡(Hadoop) 설치하기[#3] - 데이터 노드 생성 및 하둡 실행 (1) | 2020.03.02 |
| 하둡(Hadoop) 설치하기[#2] - 하둡 환경 설정 (0) | 2020.03.01 |